go-ethereum中ethash源码分析

本文代码大部分集中在consensus目录下
Engine
Engine就是以太坊中共识引擎,在构建Ethereum时被创建使用CreateConsensusEngine方法
CreateConsensusEngine(ctx, chainConfig, &config.Ethash, config.MinerNotify, config.MinerNoverify, chainDb),
func CreateConsensusEngine(ctx *node.ServiceContext, chainConfig *params.ChainConfig, config *ethash.Config, notify []string, noverify bool, db ethdb.Database) consensus.Engine {
if chainConfig.Clique != nil {
return clique.New(chainConfig.Clique, db)
}
switch config.PowMode {
case ethash.ModeFake:
log.Warn("Ethash used in fake mode")
return ethash.NewFaker()
case ethash.ModeTest:
log.Warn("Ethash used in test mode")
return ethash.NewTester(nil, noverify)
case ethash.ModeShared:
log.Warn("Ethash used in shared mode")
return ethash.NewShared()
default:
engine := ethash.New(ethash.Config{
CacheDir: ctx.ResolvePath(config.CacheDir),
CachesInMem: config.CachesInMem,
CachesOnDisk: config.CachesOnDisk,
DatasetDir: config.DatasetDir,
DatasetsInMem: config.DatasetsInMem,
DatasetsOnDisk: config.DatasetsOnDisk,
}, notify, noverify)
engine.SetThreads(-1) // Disable CPU mining
return engine
}
}首先如果需要PoA共识的话,创建clique对象。对于PoW共识的话根据不同模式创建不同的ethash对象。
对于CreateConsensusEngine是返回的一个Engine类型对象,它是一个接口,定义如下
// go-ethereum\consensus\consensus.go
type Engine interface {
Author(header *types.Header) (common.Address, error)
VerifyHeader(chain ChainReader, header *types.Header, seal bool) error
VerifyHeaders(chain ChainReader, headers []*types.Header, seals []bool) (chan<- struct{}, <-chan error)
VerifyUncles(chain ChainReader, block *types.Block) error
VerifySeal(chain ChainReader, header *types.Header) error
Prepare(chain ChainReader, header *types.Header) error
Finalize(chain ChainReader, header *types.Header, state *state.StateDB, txs []*types.Transaction,
uncles []*types.Header, receipts []*types.Receipt) (*types.Block, error)
Seal(chain ChainReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{}) error
SealHash(header *types.Header) common.Hash
CalcDifficulty(chain ChainReader, time uint64, parent *types.Header) *big.Int
APIs(chain ChainReader) []rpc.API
Close() error
}Author是返回挖出该区块的地址,接下来几个Verify开头的方法是用来验证对错的。Prepare用于填充区块头的难度字段。Finalize是发放奖励和组装区块。Seal用来打包区块。SealHash返回打包区块的hash。CalcDifficulty计算新区快的应有难度。
与Engine一起定义的还有一个PoW接口,它除了继承了Engine接口内容,还多一个Hashrate方法用于返回当前挖矿的hash率。
New
本文主要介绍Ethash源码,先看其New方法:
func New(config Config, notify []string, noverify bool) *Ethash {
if config.CachesInMem <= 0 {
log.Warn("One ethash cache must always be in memory", "requested", config.CachesInMem)
config.CachesInMem = 1
}
if config.CacheDir != "" && config.CachesOnDisk > 0 {
log.Info("Disk storage enabled for ethash caches", "dir", config.CacheDir, "count", config.CachesOnDisk)
}
if config.DatasetDir != "" && config.DatasetsOnDisk > 0 {
log.Info("Disk storage enabled for ethash DAGs", "dir", config.DatasetDir, "count", config.DatasetsOnDisk)
}
ethash := &Ethash{
config: config,
caches: newlru("cache", config.CachesInMem, newCache),
datasets: newlru("dataset", config.DatasetsInMem, newDataset),
update: make(chan struct{}),
hashrate: metrics.NewMeterForced(),
workCh: make(chan *sealTask),
fetchWorkCh: make(chan *sealWork),
submitWorkCh: make(chan *mineResult),
fetchRateCh: make(chan chan uint64),
submitRateCh: make(chan *hashrate),
exitCh: make(chan chan error),
}
go ethash.remote(notify, noverify)
return ethash
}主要就是根据config信息构建一个ethash对象,我们简单回顾一下ethash的配置,首先在eth.DefaultConfig中加载了一部分默认配置信息
// go-ethereum\eth\config.go
var DefaultConfig = Config{
SyncMode: downloader.FastSync,
Ethash: ethash.Config{
CacheDir: "ethash",
CachesInMem: 2,
CachesOnDisk: 3,
DatasetsInMem: 1,
DatasetsOnDisk: 2,
},
NetworkId: 1,
LightPeers: 100,
DatabaseCache: 512,
TrieCleanCache: 256,
TrieDirtyCache: 256,
TrieTimeout: 60 * time.Minute,
MinerGasFloor: 8000000,
MinerGasCeil: 8000000,
MinerGasPrice: big.NewInt(params.GWei),
MinerRecommit: 3 * time.Second,
TxPool: core.DefaultTxPoolConfig,
GPO: gasprice.Config{
Blocks: 20,
Percentile: 60,
},
}这里给出了构建ethash的几个关键参数,还有一个config.DatasetDir是在go-ethereum\eth\config.go的init中初始化,默认是在/home/.ethash。除此之外还有一些列用户可以设定的参数,需要在启动以太坊节点后根据固定参数设置,在go-ethereum\cmd\utils\flags.go的SetEthConfig中加载参数,一般我们都没有指定特殊参数。new方法最后启动了一个goroutine运行remote方法,我们稍后再讲
Author
func (ethash *Ethash) Author(header *types.Header) (common.Address, error) {
return header.Coinbase, nil
}这个很简单就是返回区块头的Coinbase字段
VerifyHeader
func (ethash *Ethash) VerifyHeader(chain consensus.ChainReader, header *types.Header, seal bool) error {
if ethash.config.PowMode == ModeFullFake {
return nil
}
number := header.Number.Uint64()
if chain.GetHeader(header.Hash(), number) != nil {
return nil
}
parent := chain.GetHeader(header.ParentHash, number-1)
if parent == nil {
return consensus.ErrUnknownAncestor
}
return ethash.verifyHeader(chain, header, parent, false, seal)
}首先对于ModeFullFake模式下的共识对任何区块头都予以放行,不进行检测。对于需要检测的区块头,首先获取可区块的高度,接着从本地尝试获取对应高度和hash的区块头,如果能获取到,说明该区块正确。之后在本地检查了父块,如果找不到返回ErrUnknownAncestor错误。
接下来如果能找到父块,则调用verifyHeader方法进行检测
verifyHeader
func (ethash *Ethash) verifyHeader(chain consensus.ChainReader, header, parent *types.Header, uncle bool, seal bool) error {
if uint64(len(header.Extra)) > params.MaximumExtraDataSize {
return fmt.Errorf("extra-data too long: %d > %d", len(header.Extra), params.MaximumExtraDataSize)
}
if uncle {
if header.Time.Cmp(math.MaxBig256) > 0 {
return errLargeBlockTime
}
} else {
if header.Time.Cmp(big.NewInt(time.Now().Add(allowedFutureBlockTime).Unix())) > 0 {
return consensus.ErrFutureBlock
}
}
if header.Time.Cmp(parent.Time) <= 0 {
return errZeroBlockTime
}
expected := ethash.CalcDifficulty(chain, header.Time.Uint64(), parent)
if expected.Cmp(header.Difficulty) != 0 {
return fmt.Errorf("invalid difficulty: have %v, want %v", header.Difficulty, expected)
}
cap := uint64(0x7fffffffffffffff)
if header.GasLimit > cap {
return fmt.Errorf("invalid gasLimit: have %v, max %v", header.GasLimit, cap)
}
if header.GasUsed > header.GasLimit {
return fmt.Errorf("invalid gasUsed: have %d, gasLimit %d", header.GasUsed, header.GasLimit)
}
diff := int64(parent.GasLimit) - int64(header.GasLimit)
if diff < 0 {
diff *= -1
}
limit := parent.GasLimit / params.GasLimitBoundDivisor
if uint64(diff) >= limit || header.GasLimit < params.MinGasLimit {
return fmt.Errorf("invalid gas limit: have %d, want %d += %d", header.GasLimit, parent.GasLimit, limit)
}
if diff := new(big.Int).Sub(header.Number, parent.Number); diff.Cmp(big.NewInt(1)) != 0 {
return consensus.ErrInvalidNumber
}
if seal {
if err := ethash.VerifySeal(chain, header); err != nil {
return err
}
}
if err := misc.VerifyDAOHeaderExtraData(chain.Config(), header); err != nil {
return err
}
if err := misc.VerifyForkHashes(chain.Config(), header, uncle); err != nil {
return err
}
return nil
}这个是区块头验证的主要地方,基本遵循黄皮书4.3.4的所述。分以下几步:
- 验证额外数据长度度:在区块头有一个额外数据的字段Extra,它的长度要小于32字节
- 验证时间戳:时间戳最基本的要求是要大于父块的时间戳。其次对于如果是一个叔块,时间戳不能太大,代码中要求不大于2的256次方。对于普通区块,不能为未来15秒之外的区块。
- 验证总难度:首先调用CalcDifficulty计算应该难度,然后判断是否相等,关于难度的计算稍后介绍。
- 验证gas限制:首先要求不大于2^63-1,但不能小于5000。其次gaslimit还和父块中的gaslimit相关,先关公式如下:
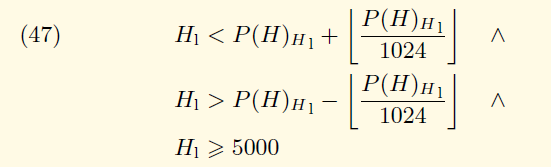
- 验证gas用量:要求小于gasLimit即可
- 验证区块高度:要求等于父块高度加一
- 其他验证:如果方法参数seal为true,执行VerifySeal方法,稍后介绍
- 验证分叉
VerifyHeaders
func (ethash *Ethash) VerifyHeaders(chain consensus.ChainReader, headers []*types.Header, seals []bool) (chan<- struct{}, <-chan error) {
if ethash.config.PowMode == ModeFullFake || len(headers) == 0 {
abort, results := make(chan struct{}), make(chan error, len(headers))
for i := 0; i < len(headers); i++ {
results <- nil
}
return abort, results
}
workers := runtime.GOMAXPROCS(0)
if len(headers) < workers {
workers = len(headers)
}
var (
inputs = make(chan int)
done = make(chan int, workers)
errors = make([]error, len(headers))
abort = make(chan struct{})
)
for i := 0; i < workers; i++ {
go func() {
for index := range inputs {
errors[index] = ethash.verifyHeaderWorker(chain, headers, seals, index)
done <- index
}
}()
}
errorsOut := make(chan error, len(headers))
go func() {
defer close(inputs)
var (
in, out = 0, 0
checked = make([]bool, len(headers))
inputs = inputs
)
for {
select {
case inputs <- in:
if in++; in == len(headers) {
inputs = nil
}
case index := <-done:
for checked[index] = true; checked[out]; out++ {
errorsOut <- errors[out]
if out == len(headers)-1 {
return
}
}
case <-abort:
return
}
}
}()
return abort, errorsOut
}这个是批量验证。首先还是对ModeFullFake模式不进行实质的验证,直接放行。接着利用一个循环,并发的执行verifyHeaderWorker方法:
func (ethash *Ethash) verifyHeaderWorker(chain consensus.ChainReader, headers []*types.Header, seals []bool, index int) error {
var parent *types.Header
if index == 0 {
parent = chain.GetHeader(headers[0].ParentHash, headers[0].Number.Uint64()-1)
} else if headers[index-1].Hash() == headers[index].ParentHash {
parent = headers[index-1]
}
if parent == nil {
return consensus.ErrUnknownAncestor
}
if chain.GetHeader(headers[index].Hash(), headers[index].Number.Uint64()) != nil {
return nil // known block
}
return ethash.verifyHeader(chain, headers[index], parent, false, seals[index])
}这里逻辑很简单,根据index验证相应的区块头,首先获取父区块,然后要验证的区块在本地是否存在,之后调用verifyHeader方法。
回到VerifyHeaders,前面的那个并发程序后河面这个匿名方法是组合使用。手下前面的for循环启动了workers个goroutine,workers表示目前可用的cpu核心数,这样做是为了尽量满负荷运行,加速验证过程。但是每个线程都在从inputs这个channel读数据的时候阻塞,这时第二个匿名函数开始执行,首先他向inputs中写入数据,写入的是要验证的区块头的index,这样前面的验证线程可以结束阻塞执行verifyHeaderWorker方法。在验证完成后,将结果写入errors中,并向done赋值,这样又触发匿名方法中select中的逻辑,这里讲错误放入errorsOut,并由errorsOut最终返回。
VerifyUncles
func (ethash *Ethash) VerifyUncles(chain consensus.ChainReader, block *types.Block) error {
if ethash.config.PowMode == ModeFullFake {
return nil
}
if len(block.Uncles()) > maxUncles {
return errTooManyUncles
}
uncles, ancestors := mapset.NewSet(), make(map[common.Hash]*types.Header)
number, parent := block.NumberU64()-1, block.ParentHash()
for i := 0; i < 7; i++ {
ancestor := chain.GetBlock(parent, number)
if ancestor == nil {
break
}
ancestors[ancestor.Hash()] = ancestor.Header()
for _, uncle := range ancestor.Uncles() {
uncles.Add(uncle.Hash())
}
parent, number = ancestor.ParentHash(), number-1
}
ancestors[block.Hash()] = block.Header()
uncles.Add(block.Hash())
for _, uncle := range block.Uncles() {
hash := uncle.Hash()
if uncles.Contains(hash) {
return errDuplicateUncle
}
uncles.Add(hash)
if ancestors[hash] != nil {
return errUncleIsAncestor
}
if ancestors[uncle.ParentHash] == nil || uncle.ParentHash == block.ParentHash() {
return errDanglingUncle
}
if err := ethash.verifyHeader(chain, uncle, ancestors[uncle.ParentHash], true, true); err != nil {
return err
}
}
return nil
}这是验证叔块的。首先也是对于ModeFullFake模式直接放行。然后检查该块的叔块数量,如果大于2报错。接着寻找了该块的父块高度和hash。之后收集了该块的祖先,最高7代。ancestors是一个map,key是hash类型,value是header类型,它存储着从该块的父块开始连续寻找7个祖先块的区块头,最后将自己也放入在内。uncles存储着每一代祖先的所有叔块hash以及该块自己的hash。
之后遍历该块的所有叔块,对于每个叔块,首先验证是否已经在uncles内,uncles存的是该块祖先的叔块,所以他的叔块不应包含在内。在之后验证是否在ancestors,因为ancestors是其直接祖先块,所以也不能成为其叔块。在之后叔块的父块时候包含在ancestors内,或者叔块的父块等于该块的父块,这都是不和逻辑的。最后校验每个叔块是否正确,调用verifyHeader方法
VerifySeal
func (ethash *Ethash) VerifySeal(chain consensus.ChainReader, header *types.Header) error {
return ethash.verifySeal(chain, header, false)
}
func (ethash *Ethash) verifySeal(chain consensus.ChainReader, header *types.Header, fulldag bool) error {
if ethash.config.PowMode == ModeFake || ethash.config.PowMode == ModeFullFake {
time.Sleep(ethash.fakeDelay)
if ethash.fakeFail == header.Number.Uint64() {
return errInvalidPoW
}
return nil
}
if ethash.shared != nil {
return ethash.shared.verifySeal(chain, header, fulldag)
}
if header.Difficulty.Sign() <= 0 {
return errInvalidDifficulty
}
number := header.Number.Uint64()
var (
digest []byte
result []byte
)
if fulldag {
dataset := ethash.dataset(number, true)
if dataset.generated() {
digest, result = hashimotoFull(dataset.dataset, ethash.SealHash(header).Bytes(), header.Nonce.Uint64())
runtime.KeepAlive(dataset)
} else {
// Dataset not yet generated, don't hang, use a cache instead
fulldag = false
}
}
if !fulldag {
cache := ethash.cache(number)
size := datasetSize(number)
if ethash.config.PowMode == ModeTest {
size = 32 * 1024
}
digest, result = hashimotoLight(size, cache.cache, ethash.SealHash(header).Bytes(), header.Nonce.Uint64())
runtime.KeepAlive(cache)
}
if !bytes.Equal(header.MixDigest[:], digest) {
return errInvalidMixDigest
}
target := new(big.Int).Div(two256, header.Difficulty)
if new(big.Int).SetBytes(result).Cmp(target) > 0 {
return errInvalidPoW
}
return nil
}这个方法用来检测区块是否满足PoW的难度要求,主要是验证nonce。首先对于ModeFake和ModeFullFake不进行检测。另外如果是shared模式,则采用对应的verifySeal方法。接下来检测区块头的难度值必须大于0.接下来根据fulldag的具体情况执行不同逻辑。
如果fullgdag为true,则先加载对应数据集,如果数据集已经产生则使用hashimotoFull进行验证,否则fulldag置为false。如果fullgad为false,则加载对应的随机数集cache,然后计算数据集大小,之后用hashimotoLight进行验证。这两处都用了KeepAlive方法,这是告诉编译器不要回收给定代码的内存。
验证之后返回两个结果digest和result,按照下面公式进行验证:
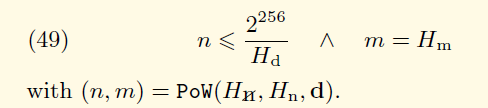 。
。
其中的n就是result,m就是digest。Hd表示该区块的难度;Hm表示该区块头的mixHash字段,是一个256位的哈希值,用来与nonce一起证明当前区块已经承载了足够的计算量。上图中的PoW函数的第一个参数表示不包含nonce和mixHash的区块头,也就是SealHash方法所产生的。
Prepare
func (ethash *Ethash) Prepare(chain consensus.ChainReader, header *types.Header) error {
parent := chain.GetHeader(header.ParentHash, header.Number.Uint64()-1)
if parent == nil {
return consensus.ErrUnknownAncestor
}
header.Difficulty = ethash.CalcDifficulty(chain, header.Time.Uint64(), parent)
return nil
}这个方法首先查找了给定区块头的父区块,然后计算了难度。
Finalize
func (ethash *Ethash) Finalize(chain consensus.ChainReader, header *types.Header, state *state.StateDB, txs []*types.Transaction, uncles []*types.Header, receipts []*types.Receipt) (*types.Block, error) {
accumulateRewards(chain.Config(), state, header, uncles)
header.Root = state.IntermediateRoot(chain.Config().IsEIP158(header.Number))
return types.NewBlock(header, txs, uncles, receipts), nil
}首先调用accumulateRewards发放奖励:
func accumulateRewards(config *params.ChainConfig, state *state.StateDB, header *types.Header, uncles []*types.Header) {
blockReward := FrontierBlockReward
if config.IsByzantium(header.Number) {
blockReward = ByzantiumBlockReward
}
if config.IsConstantinople(header.Number) {
blockReward = ConstantinopleBlockReward
}
reward := new(big.Int).Set(blockReward)
r := new(big.Int)
for _, uncle := range uncles {
r.Add(uncle.Number, big8)
r.Sub(r, header.Number)
r.Mul(r, blockReward)
r.Div(r, big8)
state.AddBalance(uncle.Coinbase, r)
r.Div(blockReward, big32)
reward.Add(reward, r)
}
state.AddBalance(header.Coinbase, reward)
}先根据区块高度决定基本的区块奖励,详细奖励发放的细节见黄皮书11.3节描述。如果是拜占庭版本也就是区块高度大于4370000,每个区块基本奖励为3以太币。如果是君士坦丁堡版本,也就是区块高度大于7280000,每个区块基本奖励为2以太币。如果区块高度低于4370000,则是5以太币。之后遍历所有叔块,每多一个叔块,奖励提高三十二分之一的基本区块奖励。对于每个叔块也有其相应奖励,公式如下:
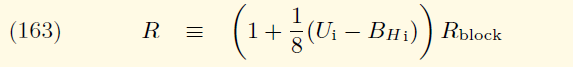
上面公式用Ui表示叔块高度,BHi表示当前区块高度,Rblock表示表示基本区块奖励。每计算一个叔块用state的AddBalance修改对应地址的余额。最后修改该区块头的coinbase余额,奖励发放完毕。
回到Finalize,计算新状态的状态树根hash,然后染回一个新的区块。
CalcDifficulty
这是一个计算难度的方法,用于计算一个区块应有的难度。
func (ethash *Ethash) CalcDifficulty(chain consensus.ChainReader, time uint64, parent *types.Header) *big.Int {
return CalcDifficulty(chain.Config(), time, parent)
}
func CalcDifficulty(config *params.ChainConfig, time uint64, parent *types.Header) *big.Int {
next := new(big.Int).Add(parent.Number, big1)
switch {
case config.IsConstantinople(next):
return calcDifficultyConstantinople(time, parent)
case config.IsByzantium(next):
return calcDifficultyByzantium(time, parent)
case config.IsHomestead(next):
return calcDifficultyHomestead(time, parent)
default:
return calcDifficultyFrontier(time, parent)
}
}这里首先计算该区块多对应的版本号,简单说一下不同版本的划分,高度在7280000以上的为君士坦丁堡版本;高度在4370000以上的为拜占庭版本;高度在1150000以上的为家园(Homestead)版本;最后高度在1150000一下的为前沿(Frontier)版本。其中君士坦丁堡版本和拜占庭版本都调用了makeDifficultyCalculator方法,区别是其中的参数不同,这个参数为了推迟难度炸弹的来临,关于难度计算是根据黄皮书中的公式计算的,这里讲一下公式,公式如下:
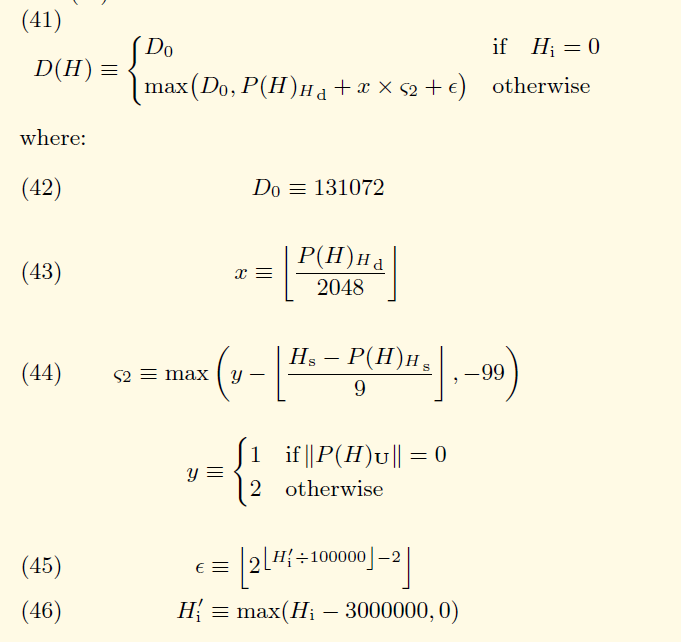
公式(41)描述了难度的计算,首先创世区块为131072,转为16进制表示就是0x20000,这就是官网给的创世区块json示例中的难度值。对于非创世区块则在两个值中取一个最大值。第一个值就是创世区块的难度。第二个值由三部分组成:
- P(H)Hd表示父区块难度
- x表示父区块的难度除以2048并向下取整。与x相乘的有一个系数,由公式(44)计算。这个公式中y有父区块的叔块数量决定,如果叔块数量为0则取1,否则取2.公式(44)中的Hs表示当前区块的时间戳,P(H)Hs表示父区块的时间戳。
- 第三部分由公式(45)(46)联合计算,这里在以太坊初始版本中没有公式(46),直接是用区块高度除以100000,由于是做指数运算,会使第三部分的值每十万个区块指数增长一次,难度值会越来越夸张,所以从拜占庭版本开始对区块高度减去一个值,拜占庭版本是3000000,君士坦丁堡版本是5000000。公式中的Hi就是区块高度。
区块的难度就由上面的公式计算的,代码也都是一些数学运算,这里不再叙述了。
关于难度计算通过公式可以看到也是动态调整的,首先它是基于父块的难度,然后难度的第二部分,当两个区块时间间隔过近时,x的系数为正,加大难度;当两个区块时间间隔过远时,x的系数为负数,减小难度值。最后一部分则会根据区块高度稳定增加一定的难度。
Seal
这个方法就是尝试找到一个nonce去满足PoW要求,然后封装一个区块
func (ethash *Ethash) Seal(chain consensus.ChainReader, block *types.Block, results chan<- *types.Block, stop <-chan struct{}) error {
if ethash.config.PowMode == ModeFake || ethash.config.PowMode == ModeFullFake {
header := block.Header()
header.Nonce, header.MixDigest = types.BlockNonce{}, common.Hash{}
select {
case results <- block.WithSeal(header):
default:
log.Warn("Sealing result is not read by miner", "mode", "fake", "sealhash", ethash.SealHash(block.Header()))
}
return nil
}
if ethash.shared != nil {
return ethash.shared.Seal(chain, block, results, stop)
}
abort := make(chan struct{})
ethash.lock.Lock()
threads := ethash.threads
if ethash.rand == nil {
seed, err := crand.Int(crand.Reader, big.NewInt(math.MaxInt64))
if err != nil {
ethash.lock.Unlock()
return err
}
ethash.rand = rand.New(rand.NewSource(seed.Int64()))
}
ethash.lock.Unlock()
if threads == 0 {
threads = runtime.NumCPU()
}
if threads < 0 {
threads = 0 // Allows disabling local mining without extra logic around local/remote
}
if ethash.workCh != nil {
ethash.workCh <- &sealTask{block: block, results: results}
}
var (
pend sync.WaitGroup
locals = make(chan *types.Block)
)
for i := 0; i < threads; i++ {
pend.Add(1)
go func(id int, nonce uint64) {
defer pend.Done()
ethash.mine(block, id, nonce, abort, locals)
}(i, uint64(ethash.rand.Int63()))
}
go func() {
var result *types.Block
select {
case <-stop:
close(abort)
case result = <-locals:
select {
case results <- result:
default:
log.Warn("Sealing result is not read by miner", "mode", "local", "sealhash", ethash.SealHash(block.Header()))
}
close(abort)
case <-ethash.update:
close(abort)
if err := ethash.Seal(chain, block, results, stop); err != nil {
log.Error("Failed to restart sealing after update", "err", err)
}
}
pend.Wait()
}()
return nil
}首先对于ModeFake或ModeFullFake模式,直接打包一个区块,nonce为0。另外如果为shared模式则调用对应的Seal方法。
接下来ethash.threads获取挖矿线程数,如果为0的话表示线程数等于cpu核数,如果小于0则禁用。接着如果随机数种子为空,则生成一个。接着启动threads个goroutine去执行mine方法。另外在外面还有一个独立的goroutine执行一个匿名方法,用于接受信号执行响应逻辑。stop读到信号表示终止操作;locals读到信号表示有线程找到了合法值;update收到信号表示进行重启。最后这个方法会等待前面执行mine的goroutine都结束才会退出。
mine
func (ethash *Ethash) mine(block *types.Block, id int, seed uint64, abort chan struct{}, found chan *types.Block) {
var (
header = block.Header()
hash = ethash.SealHash(header).Bytes()
target = new(big.Int).Div(two256, header.Difficulty)
number = header.Number.Uint64()
dataset = ethash.dataset(number, false)
)
var (
attempts = int64(0)
nonce = seed
)
logger := log.New("miner", id)
logger.Trace("Started ethash search for new nonces", "seed", seed)
search:
for {
select {
case <-abort:
logger.Trace("Ethash nonce search aborted", "attempts", nonce-seed)
ethash.hashrate.Mark(attempts)
break search
default:
attempts++
if (attempts % (1 << 15)) == 0 {
ethash.hashrate.Mark(attempts)
attempts = 0
}
digest, result := hashimotoFull(dataset.dataset, hash, nonce)
if new(big.Int).SetBytes(result).Cmp(target) <= 0 {
header = types.CopyHeader(header)
header.Nonce = types.EncodeNonce(nonce)
header.MixDigest = common.BytesToHash(digest)
select {
case found <- block.WithSeal(header):
logger.Trace("Ethash nonce found and reported", "attempts", nonce-seed, "nonce", nonce)
case <-abort:
logger.Trace("Ethash nonce found but discarded", "attempts", nonce-seed, "nonce", nonce)
}
break search
}
nonce++
}
}
runtime.KeepAlive(dataset)
}这个方法才是实际上寻找nonce的方法,基本逻辑从后面的for循环开始,从给定的seed开始,每次加一,利用hashimotoFull计算digest和result,就和前面的VerifySeal方法一样,只要result小于target即可。target等于2^256除以区块的难度。
如果找到的话给区块头补充nonce和misdigest字段,并通过WithSeal产生一个区块赋值给found,found就是前面Seal中的locals。
Ethash算法
官方文档有详细的叙述,这里简单描述一下。
Ethash是以太坊中PoW的主要算法,基本流程如下:
- 根据区块高度计算出一个seed
- 根据seed产生一个16MB伪随机数据集cache
- 根据cache产生一个1GB大小的数据集DAG,一般完全节点需要DAG,轻客户端只需要cache
- 从DAG中随机选出元素,对其进行hash运算,看是否满足要求
- 数据集30000个区块更新一次,约100小时,并且会线性增长,DAG每次增长8MB,cache每次128KB。(之所以是100小时,目的是为了在18月左右增长一倍,符合摩尔定律)
数据结构
type cache struct {
epoch uint64 // Epoch for which this cache is relevant
dump *os.File // File descriptor of the memory mapped cache
mmap mmap.MMap // Memory map itself to unmap before releasing
cache []uint32 // The actual cache data content (may be memory mapped)
once sync.Once // Ensures the cache is generated only once
}
type dataset struct {
epoch uint64 // Epoch for which this cache is relevant
dump *os.File // File descriptor of the memory mapped cache
mmap mmap.MMap // Memory map itself to unmap before releasing
dataset []uint32 // The actual cache data content
once sync.Once // Ensures the cache is generated only once
done uint32 // Atomic flag to determine generation status
}cache生成
前面在verifySeal方法中就通过cache获取了对应的cache
func (ethash *Ethash) cache(block uint64) *cache {
epoch := block / epochLength
currentI, futureI := ethash.caches.get(epoch)
current := currentI.(*cache)
current.generate(ethash.config.CacheDir, ethash.config.CachesOnDisk, ethash.config.PowMode == ModeTest)
if futureI != nil {
future := futureI.(*cache)
go future.generate(ethash.config.CacheDir, ethash.config.CachesOnDisk, ethash.config.PowMode == ModeTest)
}
return current
}第一步计算了代数,就是区块高度除以30000,然后从caches从尝试获取cache,caches的get获取所需代数及下一代的cache。
func (lru *lru) get(epoch uint64) (item, future interface{}) {
lru.mu.Lock()
defer lru.mu.Unlock()
item, ok := lru.cache.Get(epoch)
if !ok {
if lru.future > 0 && lru.future == epoch {
item = lru.futureItem
} else {
log.Trace("Requiring new ethash "+lru.what, "epoch", epoch)
item = lru.new(epoch)
}
lru.cache.Add(epoch, item)
}
if epoch < maxEpoch-1 && lru.future < epoch+1 {
log.Trace("Requiring new future ethash "+lru.what, "epoch", epoch+1)
future = lru.new(epoch + 1)
lru.future = epoch + 1
lru.futureItem = future
}
return item, future
}lru.cache是一个lru类型的缓存,先从中获取指定代数的,如果没有尝试从futureItem中获取,futureItem永远存储着下一代的cache,当然最开始为空。如果都没有新建一个。不管从哪里取到的话,如果代数低于最大代数,而且future需要更新的话,就更新future与futureItem。
我们再看新建方法:
func newCache(epoch uint64) interface{} {
return &cache{epoch: epoch}
}就是新建一个cache对象。回到cache方法,调用了generate方法
func (c *cache) generate(dir string, limit int, test bool) {
c.once.Do(func() {
size := cacheSize(c.epoch*epochLength + 1)
seed := seedHash(c.epoch*epochLength + 1)
if test {
size = 1024
}
if dir == "" {
c.cache = make([]uint32, size/4)
generateCache(c.cache, c.epoch, seed)
return
}
var endian string
if !isLittleEndian() {
endian = ".be"
}
path := filepath.Join(dir, fmt.Sprintf("cache-R%d-%x%s", algorithmRevision, seed[:8], endian))
logger := log.New("epoch", c.epoch)
runtime.SetFinalizer(c, (*cache).finalizer)
var err error
c.dump, c.mmap, c.cache, err = memoryMap(path)
if err == nil {
logger.Debug("Loaded old ethash cache from disk")
return
}
logger.Debug("Failed to load old ethash cache", "err", err)
c.dump, c.mmap, c.cache, err = memoryMapAndGenerate(path, size, func(buffer []uint32) { generateCache(buffer, c.epoch, seed) })
if err != nil {
logger.Error("Failed to generate mapped ethash cache", "err", err)
c.cache = make([]uint32, size/4)
generateCache(c.cache, c.epoch, seed)
}
for ep := int(c.epoch) - limit; ep >= 0; ep-- {
seed := seedHash(uint64(ep)*epochLength + 1)
path := filepath.Join(dir, fmt.Sprintf("cache-R%d-%x%s", algorithmRevision, seed[:8], endian))
os.Remove(path)
}
})
}首先计算了cache大小,使用cacheSize方法,如果代数小于2048(按30000块一代,2048代有61440000个区块,需要二十几年才能生成)则根据预先计算好的表查找,否则先计算size = 初始值(128MB) + 128KB * 代数 - 64B,然后验证size/64取整后是否为质数,否则size减去128在验证,循环递减直到size/64取整后为质数。对于测试模式直接设为1024.
第二步计算了seed,如果是第零代区块,直接返回一个空的长度为32的字节数组。否则对那个空字节数组循环做n次keccak256哈希运算,n就是区块所在代数。总之seed是一个256位的数据
接着组装了本地的存储文件,接下来的runtime.SetFinalizer方法是设置cache被回收时执行的方法。接着调用memoryMap将加载文件并在内存中映射,这个方法如果不报错说明之前在磁盘有旧文件,可以直接用。否则需要生成cache文件。
func memoryMapAndGenerate(path string, size uint64, generator func(buffer []uint32)) (*os.File, mmap.MMap, []uint32, error) {
if err := os.MkdirAll(filepath.Dir(path), 0755); err != nil {
return nil, nil, nil, err
}
temp := path + "." + strconv.Itoa(rand.Int())
dump, err := os.Create(temp)
if err != nil {
return nil, nil, nil, err
}
if err = dump.Truncate(int64(len(dumpMagic))*4 + int64(size)); err != nil {
return nil, nil, nil, err
}
mem, buffer, err := memoryMapFile(dump, true)
if err != nil {
dump.Close()
return nil, nil, nil, err
}
copy(buffer, dumpMagic)
data := buffer[len(dumpMagic):]
generator(data)
if err := mem.Unmap(); err != nil {
return nil, nil, nil, err
}
if err := dump.Close(); err != nil {
return nil, nil, nil, err
}
if err := os.Rename(temp, path); err != nil {
return nil, nil, nil, err
}
return memoryMap(path)
}首先创建目录,然后创建一个临时文件,接着调用Truncate方法修改临时文件大小,大小为8+size。接着映射该临时文件到内存,用的是memoryMapFile方法,我们具体看一下:
func memoryMapFile(file *os.File, write bool) (mmap.MMap, []uint32, error) {
flag := mmap.RDONLY
if write {
flag = mmap.RDWR
}
mem, err := mmap.Map(file, flag, 0)
if err != nil {
return nil, nil, err
}
header := *(*reflect.SliceHeader)(unsafe.Pointer(&mem))
header.Len /= 4
header.Cap /= 4
return mem, *(*[]uint32)(unsafe.Pointer(&header)), nil
}首先设置模式,只读或是可读写。接着调用mmap.Map方法,这是”github.com/edsrzf/mmap-go”的库。mmap将一个文件或者其它对象映射进内存,让用户程序直接访问设备内存,这种机制,相比较在用户空间和内核空间互相拷贝数据,效率更高。Map方法返回一个MMap对象,翻阅源码实际就是字节数组。接下来将MMap转为一个切片(切片实际就是SliceHeader类型),这里将切片的长度和容器都缩减到原来四分之一,这是因为原来是字节数组,后面要改为uin32数组,之后有将修改过的切片转为32位无符号整形数组连同MMap一起返回。
回到memoryMapAndGenerate中,这里将dumpMagic拷贝到刚才返回的那个uint32数组中,dumpMagic是预置的一个含有两个魔法数的数组。接着调用generator生成数据,实际上是generateCache方法
func generateCache(dest []uint32, epoch uint64, seed []byte) {
logger := log.New("epoch", epoch)
start := time.Now()
defer func() {
elapsed := time.Since(start)
logFn := logger.Debug
if elapsed > 3*time.Second {
logFn = logger.Info
}
logFn("Generated ethash verification cache", "elapsed", common.PrettyDuration(elapsed))
}()
header := *(*reflect.SliceHeader)(unsafe.Pointer(&dest))
header.Len *= 4
header.Cap *= 4
cache := *(*[]byte)(unsafe.Pointer(&header))
size := uint64(len(cache))
rows := int(size) / hashBytes
var progress uint32
done := make(chan struct{})
defer close(done)
go func() {
for {
select {
case <-done:
return
case <-time.After(3 * time.Second):
logger.Info("Generating ethash verification cache", "percentage", atomic.LoadUint32(&progress)*100/uint32(rows)/4, "elapsed", common.PrettyDuration(time.Since(start)))
}
}
}()
keccak512 := makeHasher(sha3.NewLegacyKeccak512())
keccak512(cache, seed)
for offset := uint64(hashBytes); offset < size; offset += hashBytes {
keccak512(cache[offset:], cache[offset-hashBytes:offset])
atomic.AddUint32(&progress, 1)
}
temp := make([]byte, hashBytes)
for i := 0; i < cacheRounds; i++ {
for j := 0; j < rows; j++ {
var (
srcOff = ((j - 1 + rows) % rows) * hashBytes
dstOff = j * hashBytes
xorOff = (binary.LittleEndian.Uint32(cache[dstOff:]) % uint32(rows)) * hashBytes
)
bitutil.XORBytes(temp, cache[srcOff:srcOff+hashBytes], cache[xorOff:xorOff+hashBytes])
keccak512(cache[dstOff:], temp)
atomic.AddUint32(&progress, 1)
}
}
if !isLittleEndian() {
swap(cache)
}
}传入的参数有三个。第一个就是生成的数据要填充的数组,也就是前面映射文件时返回的一个数组,第二个是区块所在代数,第三个是开始计算的种子。cache生成流程如下:
第一步将传进来的数组转为切片,然后长度和容量都乘以4。这里有几个大小需要注意,首先创建临时文件时大小是8+size,映射完返回的buffer容量是2+cap/4,之后前两个字节被写入固定值,之后剩余cap/4容量被传过来,这里又乘以4,进行了恢复,目的是为了将uint32数组转为字节数组,一个uint32等于4个字节长度。之后再将切片转为字节数组。然后计算大小size和轮数rows。接着启动一个goroutine,里面有一个for-select结构,每3秒打印一个log,显示cache生成进度。
第二步,准备一个hash函数–keccak512,keccak512(cache, seed)方法表示对seed计算hash值并写入cache中。此时cache的前512位也就是前64个字节
第三步开始一个循环,对cache进行预填充,每512位一组即64字节,第一组是对seed进行hash后的结果,之后每一组都是对前一组的hash。
第四步开始主循环,外循环有3轮,内循环轮数为第一步计算的rows。这一步连同上一步合起来是一种叫RandMemoHash的函数,是一种内存困难型的计算,详细内容参见原文或者译文。这里不再叙述,只是说一下几个方法的作用,XORBytes接受三个参数,作用是将第二个和第三个参数异或后的结果放入第一个参数中。keccak512是对第二个参数做hash运算,结果放入第一个参数。
经过上面第四步的循环后,cache被填满,最后还要保证cache中的数据时小端模式。注意cache是由header转换类型而来的,header则是的dest转换类型而来的,所以最后dest中也填满了数据。
最后cache中是若干组数据,每组有64个字节,也就是512位数据。
再回到memoryMapAndGenerate中,经过generator方法后,data填充了数据,data是buffer从2开始的切片,buffer前两个索引被放入的魔法数字,此时buffer也是有数据的。接着解除映射,这一步会将刚才内存中的数据写入文件,但注意此时还是那个temp临时文件,这里对其重命名,然后调用memoryMap
func memoryMap(path string) (*os.File, mmap.MMap, []uint32, error) {
file, err := os.OpenFile(path, os.O_RDONLY, 0644)
if err != nil {
return nil, nil, nil, err
}
mem, buffer, err := memoryMapFile(file, false)
if err != nil {
file.Close()
return nil, nil, nil, err
}
for i, magic := range dumpMagic {
if buffer[i] != magic {
mem.Unmap()
file.Close()
return nil, nil, nil, ErrInvalidDumpMagic
}
}
return file, mem, buffer[len(dumpMagic):], err
}这里再次对文件进行映射,只不过这次时只读模式,然后检查开头两个魔法数字来判断格式是否正确,然后返回文件句柄,映射对象,实际数据。
再往前回到cache的generate方法,memoryMapAndGenerate结束后,返回的几个值分别赋给了cache的几个成员,其中cache就是实际数据。接着判断前一步是否有错,有错的话则不映射文件直接生成数据。最后删除之前一些旧的文件。
最后回到Ethash的cache方法,此时我们只是生成的当前代的cache,接下来,为了方便,我们在生成下一代的cache,不过是在一个独立的goroutine中生成,方法一样,最后返回当前代的cache。
dataset生成
同样在verifySeal方法中也有获取dateset的方法,用的是ethash的dataset方法
func (ethash *Ethash) dataset(block uint64, async bool) *dataset {
epoch := block / epochLength
currentI, futureI := ethash.datasets.get(epoch)
current := currentI.(*dataset)
if async && !current.generated() {
go func() {
current.generate(ethash.config.DatasetDir, ethash.config.DatasetsOnDisk, ethash.config.PowMode == ModeTest)
if futureI != nil {
future := futureI.(*dataset)
future.generate(ethash.config.DatasetDir, ethash.config.DatasetsOnDisk, ethash.config.PowMode == ModeTest)
}
}()
} else {
current.generate(ethash.config.DatasetDir, ethash.config.DatasetsOnDisk, ethash.config.PowMode == ModeTest)
if futureI != nil {
future := futureI.(*dataset)
go future.generate(ethash.config.DatasetDir, ethash.config.DatasetsOnDisk, ethash.config.PowMode == ModeTest)
}
}
return current
}前三行和cache一样,都尝试获取当前和下一代的数据集,接着判断当前代的dataset是否已经生成,没有的话调用generate
func (d *dataset) generate(dir string, limit int, test bool) {
d.once.Do(func() {
defer atomic.StoreUint32(&d.done, 1)
csize := cacheSize(d.epoch*epochLength + 1)
dsize := datasetSize(d.epoch*epochLength + 1)
seed := seedHash(d.epoch*epochLength + 1)
if test {
csize = 1024
dsize = 32 * 1024
}
if dir == "" {
cache := make([]uint32, csize/4)
generateCache(cache, d.epoch, seed)
d.dataset = make([]uint32, dsize/4)
generateDataset(d.dataset, d.epoch, cache)
return
}
var endian string
if !isLittleEndian() {
endian = ".be"
}
path := filepath.Join(dir, fmt.Sprintf("full-R%d-%x%s", algorithmRevision, seed[:8], endian))
logger := log.New("epoch", d.epoch)
runtime.SetFinalizer(d, (*dataset).finalizer)
d.dump, d.mmap, d.dataset, err = memoryMap(path)
if err == nil {
logger.Debug("Loaded old ethash dataset from disk")
return
}
logger.Debug("Failed to load old ethash dataset", "err", err)
cache := make([]uint32, csize/4)
generateCache(cache, d.epoch, seed)
d.dump, d.mmap, d.dataset, err = memoryMapAndGenerate(path, dsize, func(buffer []uint32) { generateDataset(buffer, d.epoch, cache) })
if err != nil {
logger.Error("Failed to generate mapped ethash dataset", "err", err)
d.dataset = make([]uint32, dsize/2)
generateDataset(d.dataset, d.epoch, cache)
}
for ep := int(d.epoch) - limit; ep >= 0; ep-- {
seed := seedHash(uint64(ep)*epochLength + 1)
path := filepath.Join(dir, fmt.Sprintf("full-R%d-%x%s", algorithmRevision, seed[:8], endian))
os.Remove(path)
}
})
}这里首先计算了对应代的cache大小和种子seed,和前面cache中一样,不在叙述。除此之外还计算了dateset大小:
func datasetSize(block uint64) uint64 {
epoch := int(block / epochLength)
if epoch < maxEpoch {
return datasetSizes[epoch]
}
return calcDatasetSize(epoch)
}
func calcDatasetSize(epoch int) uint64 {
size := datasetInitBytes + datasetGrowthBytes*uint64(epoch) - mixBytes
for !new(big.Int).SetUint64(size / mixBytes).ProbablyPrime(1) { // Always accurate for n < 2^64
size -= 2 * mixBytes
}
return size
}和计算cachesize一样,对于2048代以内是查表,超过2048代是size=1GB+8MB*代数-128B,同样还是要求size除以128为质数,否则减去256在判断,如此循环直到为质数为止。
回到generate中,如果是测试模式,则设置cache的大小为1024,dateset大小为32*1024。接着如果没有指定目录的话,则不用文件映射,直接先生成一个cache,之后再生成dateset
func generateDataset(dest []uint32, epoch uint64, cache []uint32) {
logger := log.New("epoch", epoch)
start := time.Now()
defer func() {
elapsed := time.Since(start)
logFn := logger.Debug
if elapsed > 3*time.Second {
logFn = logger.Info
}
logFn("Generated ethash verification cache", "elapsed", common.PrettyDuration(elapsed))
}()
swapped := !isLittleEndian()
header := *(*reflect.SliceHeader)(unsafe.Pointer(&dest))
header.Len *= 4
header.Cap *= 4
dataset := *(*[]byte)(unsafe.Pointer(&header))
threads := runtime.NumCPU()
size := uint64(len(dataset))
var pend sync.WaitGroup
pend.Add(threads)
var progress uint32
for i := 0; i < threads; i++ {
go func(id int) {
defer pend.Done()
keccak512 := makeHasher(sha3.NewLegacyKeccak512())
batch := uint32((size + hashBytes*uint64(threads) - 1) / (hashBytes * uint64(threads)))
first := uint32(id) * batch
limit := first + batch
if limit > uint32(size/hashBytes) {
limit = uint32(size / hashBytes)
}
percent := uint32(size / hashBytes / 100)
for index := first; index < limit; index++ {
item := generateDatasetItem(cache, index, keccak512)
if swapped {
swap(item)
}
copy(dataset[index*hashBytes:], item)
if status := atomic.AddUint32(&progress, 1); status%percent == 0 {
logger.Info("Generating DAG in progress", "percentage", uint64(status*100)/(size/hashBytes), "elapsed", common.PrettyDuration(time.Since(start)))
}
}
}(i)
}
pend.Wait()
}这里首先对传入的dest也就是要存放数据的数组进行处理,先转为切片,修改其长度和容量,都是扩大4倍,之后再转为字节数组类型。接着获取cpu核数记为threads,获取数据集大小,然后启动threads个独立的goroutine。
首先dataset的整体数据结构和cache类似,都是按64字节也就是512位为一组,这里为了实现多线程并行计算,在每个goroutine中计算了需要计算的组数,然后循环调用generateDatasetItem生成每一组数据:
func generateDatasetItem(cache []uint32, index uint32, keccak512 hasher) []byte {
rows := uint32(len(cache) / hashWords)
mix := make([]byte, hashBytes)
binary.LittleEndian.PutUint32(mix, cache[(index%rows)*hashWords]^index)
for i := 1; i < hashWords; i++ {
binary.LittleEndian.PutUint32(mix[i*4:], cache[(index%rows)*hashWords+uint32(i)])
}
keccak512(mix, mix)
intMix := make([]uint32, hashWords)
for i := 0; i < len(intMix); i++ {
intMix[i] = binary.LittleEndian.Uint32(mix[i*4:])
}
for i := uint32(0); i < datasetParents; i++ {
parent := fnv(index^i, intMix[i%16]) % rows
fnvHash(intMix, cache[parent*hashWords:])
}
for i, val := range intMix {
binary.LittleEndian.PutUint32(mix[i*4:], val)
}
keccak512(mix, mix)
return mix
}首先把cache中的数据每16个视作一行,计算cache的总行数,由于cache每个元素时32位,16个也即是512位,也就是cache中的一组。这里初始化了一个含有64字节的数组mix,总长度也就是512位。接着按照一定规则计算mix,基本原则是充分利用cache中足够多的数据。
接着把mix中的数据放入一个长度为16的32位整型数组intmix,总长度也是512位。然后有一个循环,每次循环都利用了所谓的fnv和fnvhash函数,总循环为256次,目的还是尽可能多的使用cache中数据。每次循环的结果还是放在intmix中。(fnv全称Fowler–Noll–Vo,也是一种hash函数,他计算速度非常快,冲突率较低,也就是对于相似的数据也能产生大量的差别,其分散性较好,之所以用它是为了能较为随机的从数据集中取数据,避免数据间的使用率差别较大)
最后将intmix的数据写入mix中,再对mix做一次哈希运算,最后得到一个512位的数据,就是dataset中一组数据。
数据集的生成算法借鉴了Hashimoto算法,要想了解更多请参考Hashimoto算法,译文见这里
回到generateDataset中,调用generateDatasetItem之后,获取了一组数据,将其放到dateset对应位置,经过若干次上面过程后一个完整的dataset得以生成。
回到dataset的generate方法中,刚才我们分析的是没有指定数据存储路径的流程,接下来我们在看一下有数据路径的流程。
首先构建文件的最终路径,然后调用memoryMap进行映射,这一步和cache相同,如果没有错误说明原本就有,直接返回,读取的数据放入dataset相应字段中。如果读不到数据或有错,则先用generateCache生成cache数据,在使用memoryMapAndGenerate生成空文件,并进行映射然后生成dataset数据进行填充,流程和cache一样,不在叙述。只不过和前面直接生成数据不同的是,这里在数据开头写入了64位的魔法数字,和cache一样。最后尝试旧的数据文件,和cache一样的流程。
最后回到ethash的dataset方法,在这里主要是分了同步还是异步,逻辑都还是一样,只不过异步的是在一个单独的goroutine中执行的。最后生成完当代的dateset后,又根据具体需要生成了下一代数据。
hashimotoFull
func hashimotoFull(dataset []uint32, hash []byte, nonce uint64) ([]byte, []byte) {
lookup := func(index uint32) []uint32 {
offset := index * hashWords
return dataset[offset : offset+hashWords]
}
return hashimoto(hash, nonce, uint64(len(dataset))*4, lookup)
}这是在全节点中节点有完整dateset数据集时的验证方法,直接调用了hashimoto方法
hashimotoLight
func hashimotoLight(size uint64, cache []uint32, hash []byte, nonce uint64) ([]byte, []byte) {
keccak512 := makeHasher(sha3.NewLegacyKeccak512())
lookup := func(index uint32) []uint32 {
rawData := generateDatasetItem(cache, index, keccak512)
data := make([]uint32, len(rawData)/4)
for i := 0; i < len(data); i++ {
data[i] = binary.LittleEndian.Uint32(rawData[i*4:])
}
return data
}
return hashimoto(hash, nonce, size, lookup)
}这是没有完整dataset之后cache的轻节点的验证方法,也是直接调用了hashimoto方法,和hashimotoFull的区别是lookup的差别
hashimoto
func hashimoto(hash []byte, nonce uint64, size uint64, lookup func(index uint32) []uint32) ([]byte, []byte) {
rows := uint32(size / mixBytes)
seed := make([]byte, 40)
copy(seed, hash)
binary.LittleEndian.PutUint64(seed[32:], nonce)
seed = crypto.Keccak512(seed)
seedHead := binary.LittleEndian.Uint32(seed)
mix := make([]uint32, mixBytes/4)
for i := 0; i < len(mix); i++ {
mix[i] = binary.LittleEndian.Uint32(seed[i%16*4:])
}
temp := make([]uint32, len(mix))
for i := 0; i < loopAccesses; i++ {
parent := fnv(uint32(i)^seedHead, mix[i%len(mix)]) % rows
for j := uint32(0); j < mixBytes/hashBytes; j++ {
copy(temp[j*hashWords:], lookup(2*parent+j))
}
fnvHash(mix, temp)
}
for i := 0; i < len(mix); i += 4 {
mix[i/4] = fnv(fnv(fnv(mix[i], mix[i+1]), mix[i+2]), mix[i+3])
}
mix = mix[:len(mix)/4]
digest := make([]byte, common.HashLength)
for i, val := range mix {
binary.LittleEndian.PutUint32(digest[i*4:], val)
}
return digest, crypto.Keccak256(append(seed, digest...))
}首先根据给定的头部hash和nonce计算seed,头部hash是32字节,nonce是8字节,将其拼接后做一次keccak512哈希运算,得到一个长度为64的字节数组。接着创建了一个无符号32位整型数组,长度是32。然后将seed中的数据数据放入mix中,由于mix总位数是seed的两倍,所以mix先后放置了两个seed的数据内容。
继续向下,设置一个和mix大小一样的临时数组。开始了64次循环,每次循环还是fnv和fnvhash进行运算,其中循环中fnv即其后的那个循环是为了对temp进行填充,fnvhash是为了利用temp对mix进行运算,最后结果放入mix中。关键一点是在lookup中。对于节点有完整dataset时,lookup实现如下
lookup := func(index uint32) []uint32 {
offset := index * hashWords
return dataset[offset : offset+hashWords]
}很简单就是输入一个索引,然后从dateset中取一组数据(16个uint32数据,共512位)。对于没有完整dateset时,实现如下:
lookup := func(index uint32) []uint32 {
rawData := generateDatasetItem(cache, index, keccak512)
data := make([]uint32, len(rawData)/4)
for i := 0; i < len(data); i++ {
data[i] = binary.LittleEndian.Uint32(rawData[i*4:])
}
return data
}由于没有完整的数据,我们要根据索引去临时计算一个数据,调用的是generateDatasetItem方法,这个计算量以及内存占用都是比较少的。
回到hshimoto中,之所以用fnv以及lookup只是为了能随机的从dateset中取一个数据,这样对于挖矿节点,最优的方法是在内存中完整保留dataset数据副本,这就是内存困难型工作证明函数。经过64轮的fnv、lookup及fnvhash运算,最后得到的还是mix数组,接着对mix进行压缩,压缩为之前的四分之一,也就是128位,这就是区块头的MixDigest字段。最后将seed(512位)和digest拼接进行一次keccak256运算得到一个256位的值,挖矿也就是将这个值和难度值比较。
这里我们简要分析一下,从dataset中取数据的索引由parent和j构成,parent由seedhead(seed的前四个字节按小端序组成)和mix(mix由seed经过简单的操作生成),j则是0或1。而seed是由头结点hash和nonce组成。所以对于验证节点,只需一个完整的cache数据,然后在那64轮循环中,每次循环根据索引从cache中计算0dateset的某组数据。而对于挖矿节点,虽然也可以和验证节点一样每次都计算一组,但是由于每次是从整个dataset中随机选一组数据,虽然是伪随机的,但是也难以预测,所以最好的方法是能是保存整个数据集副本,这样就实现了内存困难型计算。
最后在验证过程中既要小于难度值,又要等于digest,所以也就强迫挖矿节点按照刚才流程来进行计算。因为最后和难度值比较的数只是seed和某个128位的值拼接后hash的结果,所以如果不比较digest,挖矿节点只用不断尝试nonce,然后计算出seed即可,digest就是使用dateset的一个证明。
geth生成数据集
为了方便我们测试,geth提供了生成数据集的命令,只用指定区块号即可
geth makecache 36000 ethash/
geth makedag 36000 ethash/关于大小端
无论是cache还是dateset中的数据都是按照小端模式存储的。所谓小端模式就是在低地址中存放低位,相反低地址存放高位就是大端模式。对于0x01020304这个数,04就是低位,01就是高位。源码中也给出了测试我们的机器是大端还是小端的代码:
func isLittleEndian() bool {
n := uint32(0x01020304)
return *(*byte)(unsafe.Pointer(&n)) == 0x04
}很简单,就是存一个数,然后取低地址看是否是低位即可,这里的取低地址就是通过指针转为字节类型,由于32位整型转为8位字节,只保留的低位数据。
关于为什么要使用小端模式,实际上无论大小端都可以,但是在计算数据集的时候存在多次uin32与[]byte的转换,如果不统一一下格式,在不同机器上就会有不同结果。同样源码也给出了转为小端模式的代码
func swap(buffer []byte) {
for i := 0; i < len(buffer); i += 4 {
binary.BigEndian.PutUint32(buffer[i:], binary.LittleEndian.Uint32(buffer[i:]))
}
}
func (littleEndian) Uint32(b []byte) uint32 {
_ = b[3] // bounds check hint to compiler; see golang.org/issue/14808
return uint32(b[0]) | uint32(b[1])<<8 | uint32(b[2])<<16 | uint32(b[3])<<24
}实际就是利用了littleEndian中的方法翻一下顺序即可。
题图来自unsplash:https://unsplash.com/photos/kDJ4i77UPe0