Hashimoto:IO限制的工作证明

摘要
使用加密哈希函数并不是为了工作证明,而是作为一个指向共享数据集的生成器,成为一个受IO约束的工作证明。这种工作证明方法很难通过ASIC设计进行优化,并且在没有完整数据集的情况下很难外包给节点。该名称基于包含算法的三个操作:散列、移位和模运算
证明这个操作是很难优化与外包的
加密货币开发中的一个常见挑战是保持网络的去中心化。使用工作证明来达成去中心化的共识,最显著的例子就是比特币,它使用了与sha256的零数量类似的部分冲突,与hashcash类似。由于比特币受欢迎程度日益高涨,已经生成了专用硬件来快速迭代基于哈希的工作证明函数(当前应用的是特点集成电路或ASICs)。与比特币类似的新项目通常使用不同的算法来证明工作,并且通常以抗ASIC为目标。对于比特币这样的算法,ASICs的改进因素意味着商用计算机硬件无法有效使用。
工作的证明也可以“外包”,或者由专用机器(“矿工”)执行,而不知道正在验证什么。在比特币的“矿池”中,情况往往如此。工作证明算法难以外包是十分有利的,他能促进去中心化,并鼓励所有参与工作证明过程的节点也对事务进行验证。考虑到这些目标,我们提出Hashimoto,一个I/O限制的工作证明算法,我们相信他可以抵抗ASIC和外包。
抵抗ASIC的最初尝试包括改变比特币的sha256算法,使之成为一种不同的、内存更密集的算法,即Percival的基于密钥推导功能的“scrypt”密码算法。许多实现将scrypt参数设置为低内存需求,这违背了密钥派生算法的大部分目的。在切换到新算法时,再加上各种基于scryptt的加密货币运行有一定延迟,目前已经有基于scrypt优化的ASICs。类似的,尝试各种变体或异构的hash函数也仅仅是推迟ASIC的实现
利用共享数据集创建I/O绑定证明
超级计算机是一种将受计算量限制的问题转换为受IO限制的问题 –Ken Batcher.
相反,如果一种算法在普通商业计算机系统以已经优化过的方式工作,那么他在一个新的设备上就不会有太大的提升。
由于I/O限制是数十年来计算机研究所致力于解决的问题,所以对挖币这种动机而言不太可能在缓存层次结构中的有技术水平的提升。如果取得进展,它们很可能会影响整个计算机硬件行业。
幸运的是,参与当前加密货币实现的所有节点都有一组彼此同意的数据,事实上,这种“区块链”也是是加密货币的基础。使用这种大型数据集既限制了专用硬件的优势,又要求工作节点拥有整个数据集。
Hashimoto是基于比特币的工作证明。就像Hashimoto一样,在比特币中成功的证明满足以下不平等条件:
hash_output < target对于比特币,hash_output由以下公式得出
hash_output = sha256(prev_hash, merkle_root, nonce)其中prev_hash是前一个块的哈希值,不能更改。merkle_root基于块中包含的事务,对于每个节点都是不同的。当计算hash_output时,如果不满足不等式,nonce会快速增加。因此,证明的瓶颈是sha256函数,提高sha256的速度或并行化是asic可以非常有效地做的事情。
Hashimoto使用这个哈希输出作为起点,用于生成第二个哈希函数的输入。我们称原始哈希为hash_output_A,以及证明的最终结果为final_output。
Hash_output_A可以从共享区块链中选择许多事务得出,然后将其用作第二个散列的输入。为了将事务组织成块,按顺序组织所有事务比较简单。例如,第815块的第47个事务可以称为事务141,918。我们将使用64个事务,尽管较高和较低的数字都可以使用,但具有不同的访问属性。我们定义了以下函数:
nonce 64位。每次尝试都会创建一个新的nonce。
get_txid(T) 从B块返回编号为T的事务的txid(事务的哈希)
block_height 区块链的当前高度,会在每个新块上增长Hashimoto通过以下操作选择事务:
hash_output_A = sha256(prev_hash, merkle_root, nonce)
for:=0 to 60 do
shifted_A = hash_output_A >> i
transaction = shifited_A mod total_transactions
txid[i] = get_txid(transaction) << i
end for
txid_mix = txid[0] xor txid[1]...xor txid[63]
final_ouput = txidmix xor (nonce << 192)然后将目标与final_output进行比较,并接受较小的值作为证明。
初始哈希输出用于独立且一致地从区块链中选择64个事务。在这64步中的每一步,hash_outputA都会右移一位,以获得一个新的数字shifted_A。通过计算shifted_A模总块数选择一个区块,通过计算shifted_A模该块的总事务数选择一个事务。这些txid的偏移量也与选择它们的shifted_A相同。一旦检索到64个txid,它们就会一起进行异或,并与原始的nonce一起用作最终哈希函数的输入。在最后的异或函数中需要原来的nonce,因为非常小的事务集可能没有包含足够多的txid排列来满足工作不平等的证明。事实上,这个算法只在区块链扩展时才成为I/O限制的。在只有一个块和一个事务的区块链的极端情况下,可以省略整个64次迭代过程,并且可以快速迭代用于计算final_output的nonce,因为txid总是相同的。对于较大的区块链,在最后的散列中包含nonce可能不再是必要的,但也不是有害的。
瓶颈分析
这种方法在哈希操作和内存访问之间进行了指数级的权衡。给定一个包含100个块的区块链,如果一个挖掘节点缺少一个块,那么每个初始哈希都有0.5的概率成为第二个哈希计算的输入。因此减少百分之一的IO需求就要付出两倍的哈希计算。百分之二的减少会付出四倍的计算。显然,采矿者需要整个区块链才能开采。
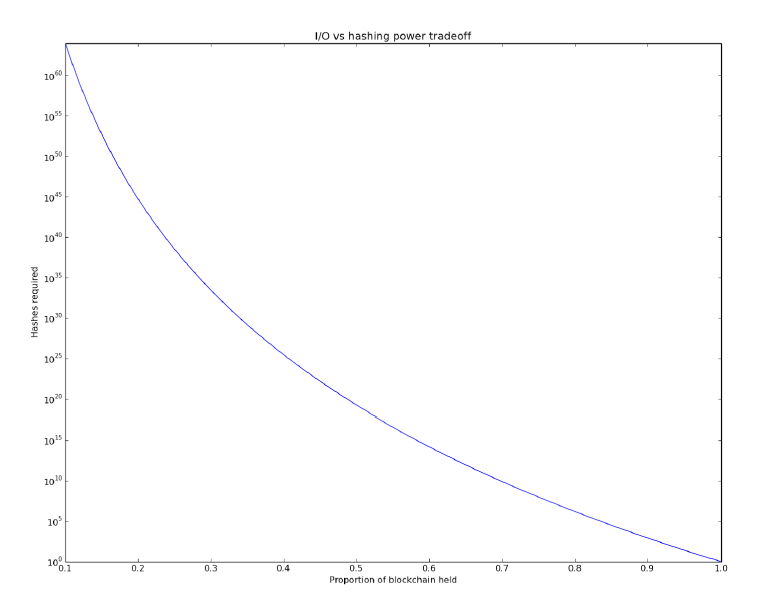
对于所有节点,这也很容易验证。接收节点只需要执行1个sha256操作,128个移位操作、64个XORs和几百个I/O操作。与块验证期间还需要的签名验证相比,验证此工作证明的成本要低得多。
这种方法不能有效地外包。如果服务器要为远程挖掘节点托管区块链,那么网络延迟将完全超过每次哈希操作的时间。在这个场景中,矿工将持有每个块中事务数量的查询表,这样他们就可以计算散列、移位、模,并找到他们需要的每个事务的txid。发送到区块链主机服务器最多需要几kb。区块链托管服务器的响应也将是2KB或稍多一点。如果将这些请求序列化,每个传输的延迟为毫秒级,这将创建每秒1000哈希数以下的限制。相反,如果矿工创建了大量txid请求,那么每个可能的散列都需要2Kb的数据通过网络。每秒运行10亿个sha256操作(用当前的硬件很容易实现)将需要每秒几tb的网络吞吐量。如果区块链小于1tb,那么整个区块链每秒需要传输多次。显然,对于每个挖掘节点来说,维护它所需的所有数据的本地副本,以便尽可能地证明工作,这样会快得多。
为这种算法开发ASIC不太可能比普通计算机硬件带来显著的改进。从比特币网络难度的增加可以看出,sha256可以通过专用硬件进行优化。然而,Hashimoto每次尝试只使用1个sha256操作,对于当前CPU,每个操作的时间都是微秒。尽管在定制硬件中,可以在低成本快速的情况下实现移位,但在通用cpu上,移位操作也非常迅速,而不是瓶颈。同样,虽然模块化操作也可以优化,但在cpu上也非常快。,Hashimoto的瓶颈是get_txid(T)函数,它需要对磁盘或RAM执行读取操作。不能有效地缓存这些I/O操作,因为每个hash_output_A指向一组完全不同的事务。
进行这种工作证明的最有效方法是由高速内存。由于哈希、移位和模操作非常快,因此可以计算和排列许多(block、tx)对,并按顺序或并行检索它们。虽然区块链很小,cpu将能够在芯片上缓存整个区块链,但是随着它的增长,将它移动到DRAM将是必要的。将txid移动到磁盘上会慢得多,并且可能会导致矿商无法与能够在DRAM中存储整个区块链的矿商竞争。如果区块链比DRAM存储增长得更快,那么会有使用无限带宽或其他低延迟、高吞吐量网络系统的多服务器。这种访问模式在许多高性能计算应用程序中很常见,几十年的研究已经为此优化了计算机硬件。
结论
通过利用加密货币区块链固有的大型共享数据存储,可以创建抗ASIC、不可外包的工作证明算法。使用加密哈希算法伪随机地从大型共享数据集中选择元素,使得哈希能力证明成为I/O能力证明,这是当前计算机硬件已经优化过的。这种I/O绑定算法还确保每个节点包含整个数据集,从而限制了集中的外包池。Hashimoto可以推出一种新的加密货币,以公平和区中心化的方式在商业计算机硬件上出现。
题图来自unsplash: https://unsplash.com/photos/Q_ffjo0m3hE