go-ethereum中trie源码学习

MPT(Merkle Patricia Tree),是以太坊实现中广泛使用的一种数据结构,如在区块头中就保存了状态树,交易树和收据树这三棵树的根的hash,而这三棵树就是MPT。MPT是Trie树、Patricia Trie树和Merkle树的变形,下面我们就来详细了解一下
背景
Trie树
Trie树又称前缀树或字典树。顾名思义一个节点的所有孩子都具有同样的前缀,就像字典一样把单词按前缀分类排序。
- 在Trie树中,根节点不保存信息,每个节点的最大孩子数量相同(若是保存英文字母,不区分大小写,则最多有26个孩子)。
- 从根节点开始,到某一节点,路径上的字符组合起来就是该节点对应的字符串
- 没有重复的节点
语言说起来比较抽象,看一张图就很清楚了
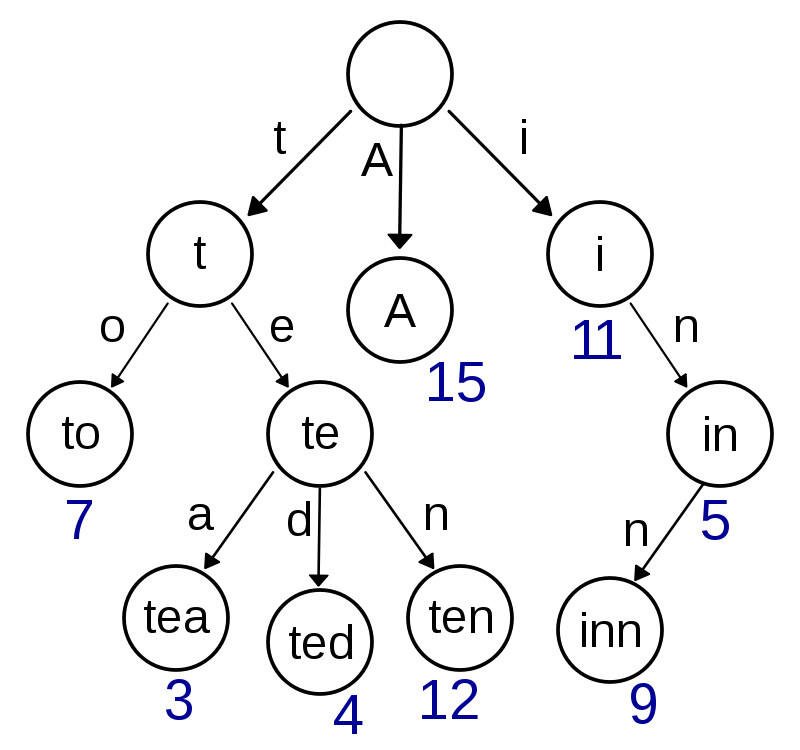
如上图所示,这棵树可能保存了:A,to,tea,ted,ten,i,in,inn这8个字符串(具体某个节点表示的仅仅是前缀还是字符串还要根据节点参数判断)。java实现见这里
Trie树具有查找效率高的特点,但是稀疏现象比较严重,空间利用率低。Trie树常用于搜索提示,如输入前几个字母,就可以很快的提示一些可能匹配的字符串。
Patricia Trie
实际上是基数树,或压缩前缀树。根据名字可知,是对前缀进行一定的压缩,为了是缓解Trie树空间利用率不高的问题。如下图
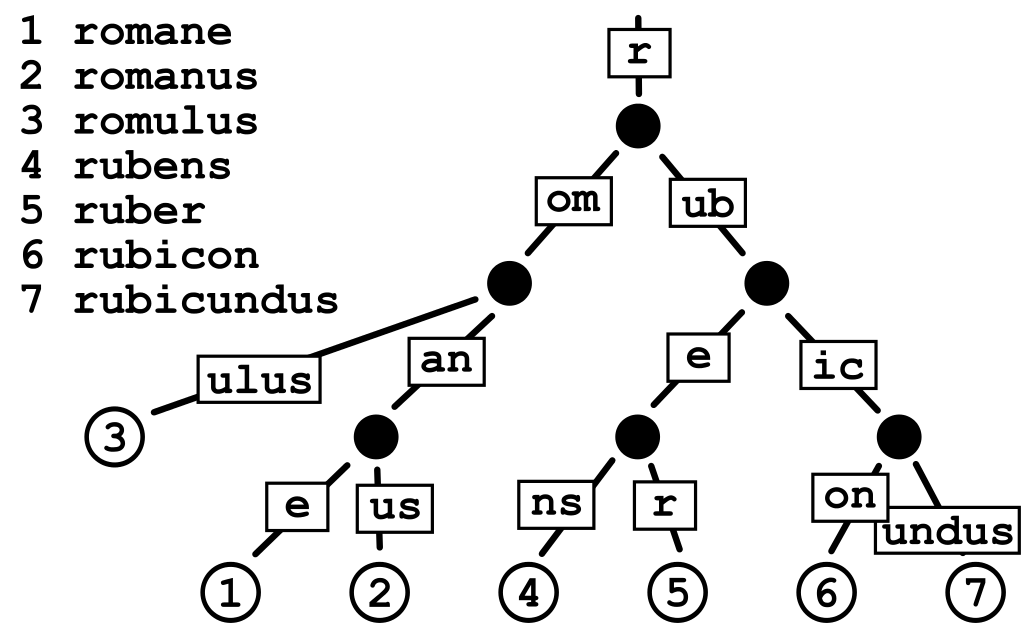
从图中我们可以知道,如果以Trie树存储romane和romanus,对于他们的公共前缀roman我们要创建5个先后依赖的节点,在第5层处分叉,对于us又需要两层节点。而对于基数树,可以把roman合并为一个节点,us也合并为一个节点,这样原本至少7层才能表示的现在2层即可。
关于这种树的实现我们会在后面源码分析提到
Merkle树
Merkle Tree,通常也被称作Hash Tree。这种树的的主要作用是验证。它结构上大多情况是一颗二叉树,叶子结点都以数据库的hash值作为标签,其他结点都是其子节点的标签拼接后再做hash。他可以高效的安全的验证大型数据结构的内容。
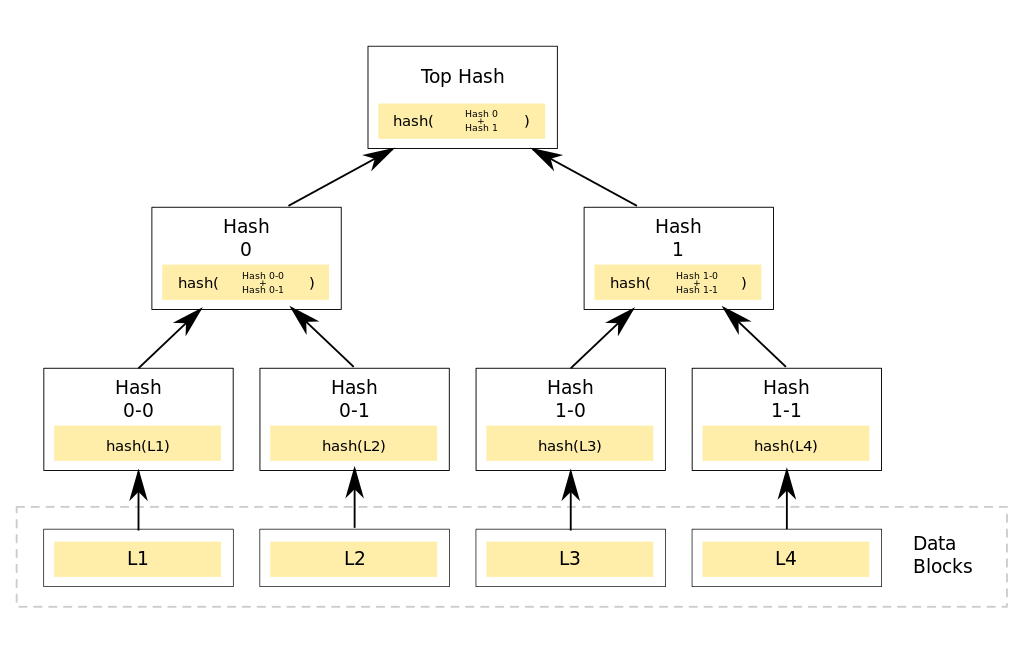
如上图,数据的每一块都对应一个叶子,叶子内存储该块的hash,之后层层做hash运算,最后得到根节点的一个hash值。我们只需要验证根节点的hash是否相同,就能判断整个文件是否完整或者是否被人恶意篡改。另外,通过重建整个树,可以很快的知道具体哪一部分出错。具体在区块链中,无论比特币还是以太坊,都是只在区块头中存储根节点,从而来判断是否一致。
以太坊的MPT
一般而言MPT的存储借鉴的是Patricia Trie。与一般的存储英文字符串不同,MPT存储的是hash值,每一位有0-f共16种可能,不过MPT又对其进行了扩展。
首先,定义了三种节点:
- branch:分支节点,一个长度为17的list,分别是0-f共16位,再加一个value。最后的value代表该节点可能对某个key是终点,用于存取值
- leaf:叶子节点,和Trie树的叶子结点类型
- extension:扩展节点,纯粹的路径节点,其中的值时其它节点hash,可以理解为一个指向其他节点的指针
看一张经典的图会比较容易理解:
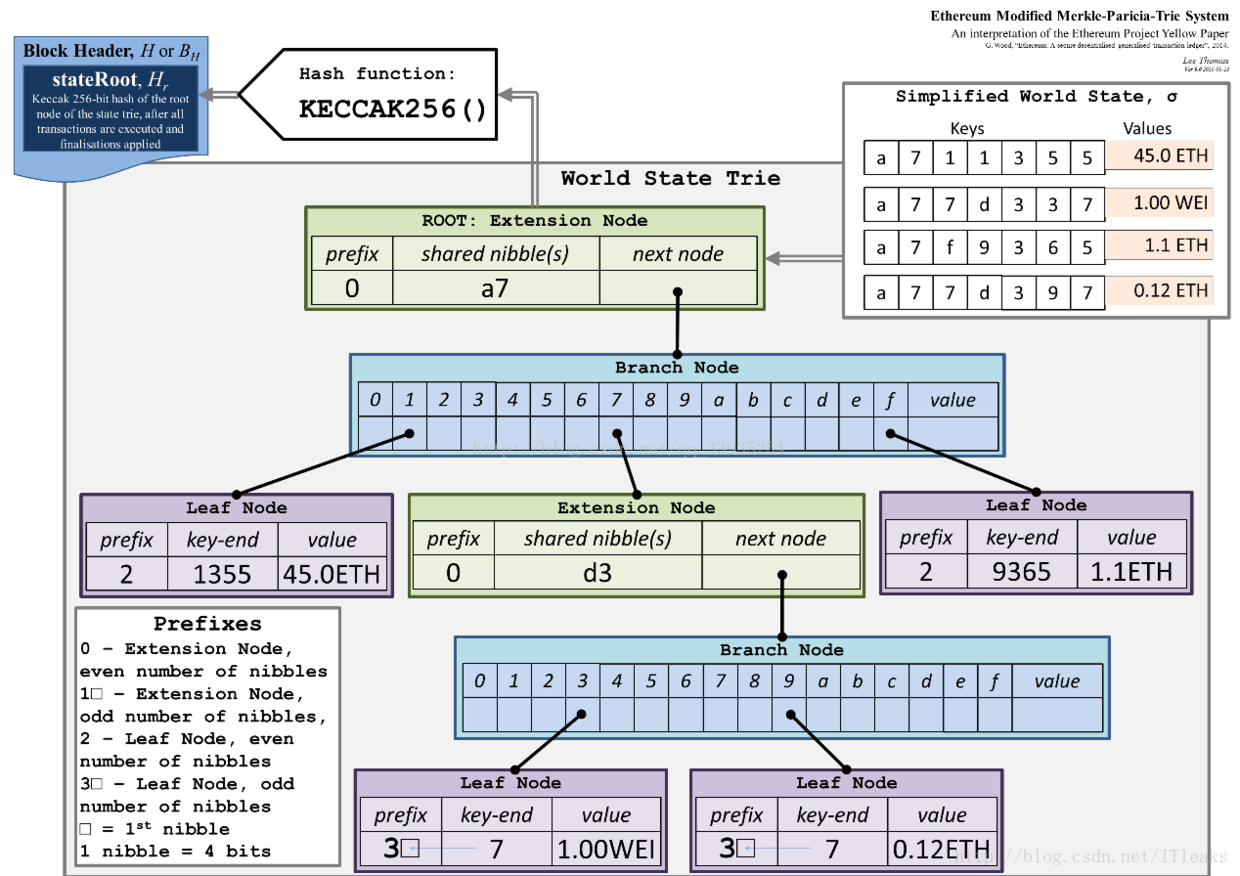
在图中,右上角四对键值就是图中树所存储的内容。首先他们都有前缀a7,所以根节点就是一个扩展节点,它的指针指向一个分支节点,分支节点用到了1、7、f三个值,1、f分别指向两个叶子节点,因为没有其他key和他们有除a7外的公共前缀,分支节点7指向一个扩展节点,因为右上角第二和第四个还有公共前缀d3,随后在指向一个分支节点,再找值分为两个叶子节点。叶子结点的value就存着每个键值对中的value.
源码分析
ethereum关于这部分的源码集中在trie目录下
结点定义
见代码:
// go-ethereum\trie\node.go
type node interface {
fstring(string) string
cache() (hashNode, bool)
canUnload(cachegen, cachelimit uint16) bool
}
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)虽说黄皮书中定义了3种结点,但这里只有两种节点,分别是fullnode和shortnode。fullnode就是分支节点,可见其有一个长度为17的数组。shortnode可以代表扩展节点或叶子节点,因为二者结构是一样的,区分两种节点主要看val的值。另外还有两种节点,虽然是字节数组类型的,但是他们都实现了node接口的全部方法,所以也是节点类型。
树的构造
先看一下树的结构:
type Trie struct {
db *Database
root node
cachegen, cachelimit uint16
}root就是根节点,db就是数据库,树的结构最后要存到数据库中,启动时再加载出来。对于cachegen,每次提交其值都会增加,新节点会标记cachegen,如果当前的cachegen - cachelimit大于node的cache时代,那么node会从cache里面卸载,以便节约内存。
创建一棵树
func New(root common.Hash, db *Database) (*Trie, error) {
if db == nil {
panic("trie.New called without a database")
}
trie := &Trie{
db: db,
}
if root != (common.Hash{}) && root != emptyRoot {
rootnode, err := trie.resolveHash(root[:], nil)
if err != nil {
return nil, err
}
trie.root = rootnode
}
return trie, nil
}new方法接受一个hash和一个数据库指针,首席确保指针不为空,然后初始化树,之后再判断传入的hash是否为空值,若不是则从数据库加载,否则返回一个空树。
插入
func (t *Trie) insert(n node, prefix, key []byte, value node) (bool, node, error) {
if len(key) == 0 {
if v, ok := n.(valueNode); ok {
return !bytes.Equal(v, value.(valueNode)), value, nil
}
return true, value, nil
}
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
if matchlen == len(n.Key) {
dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value)
if !dirty || err != nil {
return false, n, err
}
return true, &shortNode{n.Key, nn, t.newFlag()}, nil
}
branch := &fullNode{flags: t.newFlag()}
var err error
_, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val)
if err != nil {
return false, nil, err
}
_, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value)
if err != nil {
return false, nil, err
}
if matchlen == 0 {
return true, branch, nil
}
return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil
case *fullNode:
dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value)
if !dirty || err != nil {
return false, n, err
}
n = n.copy()
n.flags = t.newFlag()
n.Children[key[0]] = nn
return true, n, nil
case nil:
return true, &shortNode{key, value, t.newFlag()}, nil
case hashNode:
rn, err := t.resolveHash(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.insert(rn, prefix, key, value)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v", n, n))
}
}几个参数分别是:n代表当前的结点。prefix代表已经搜索过的前缀,key表示尚未处理的部分,二者拼接到一起就是完整的key。value表示要插入的值。返回值中bool表示是否改变了树,node表示插入后子树的根节点。通过参数可以猜到这是通过递归进行操作的。
代码的第一个if判断中,若key的长度为0,表示key已经遍历完了,同时也找到了一个节点。判断这个节点是否是valueNode类型节点,若是的话,判断要插入的值和结点的值是否相等,来判断是否改变了树。若不是valueNode类型节点,就直接更新value,同时指明树已经改变了。
若还在变量key的途中,则根据当前节点的类型进行判断:
- 若是shortNode节点,表示是一个叶子节点或扩展节点,则调用prefixLen方法计算公共前缀长度。若公共前缀长度就等于key的长度,说明二者的可以是一样的,则按照需要更新value。若只有部分公共前缀,则需要构造一个分支节点,将原来的节点和要插入的作为新分支节点的孩子插入。最后对刚才的公共前缀进行判断,若为0,表示没有公共前缀,则用新的分支节点替换掉原来的节点,若不为零,则将新的分支节点作为原节点的孩子,并改变原节点的可以。注意给分支节点添加孩子时,也是调用的insert,只不过n为nil,这对应后面的一种情况,稍后分析。
- 若是fullNode,也就是分支节点,则直接寻找对应的位置尝试插入,注意分支节点对于位置的孩子可能为空,为shortNode或者fullnode,不管为什么,最终继续递归,并按需更新孩子即可
- 若是nil,这种情况可能会一棵空树时候出现,这是新建一个shortNode节点作为根节点,返回即可。同时,在上文向分支节点插入孩子时也会出现,同样也是新建shortNode结点作为分支节点孩子即可。
- 若是hashNode,可以理解为一个指针,但是数据都在数据库,需要取数据库取值插入
- 最后不满足定义的四种节点,报错
最后总结一点,对于shortNode节点,要么进行更新,要么新建扩展节点进行插入,对于fullNode,要么成为其某个孩子,要么更新其值,要么为其添加扩展节点,进行扩展。总之新的叶子节点插入操作都是在扩展节点上完成的。
删除
func (t *Trie) delete(n node, prefix, key []byte) (bool, node, error) {
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
if matchlen < len(n.Key) {
return false, n, nil // don't replace n on mismatch
}
if matchlen == len(key) {
return true, nil, nil // remove n entirely for whole matches
}
dirty, child, err := t.delete(n.Val, append(prefix, key[:len(n.Key)]...), key[len(n.Key):])
if !dirty || err != nil {
return false, n, err
}
switch child := child.(type) {
case *shortNode:
return true, &shortNode{concat(n.Key, child.Key...), child.Val, t.newFlag()}, nil
default:
return true, &shortNode{n.Key, child, t.newFlag()}, nil
}
case *fullNode:
dirty, nn, err := t.delete(n.Children[key[0]], append(prefix, key[0]), key[1:])
if !dirty || err != nil {
return false, n, err
}
n = n.copy()
n.flags = t.newFlag()
n.Children[key[0]] = nn
pos := -1
//遍历后,若pos大于等于0,表示只有一个孩子
//若pos等于-2则孩子数量大于一个
for i, cld := range &n.Children {
if cld != nil {
if pos == -1 {
pos = i
} else {
pos = -2
break
}
}
}
if pos >= 0 {
if pos != 16 {
cnode, err := t.resolve(n.Children[pos], prefix)
if err != nil {
return false, nil, err
}
if cnode, ok := cnode.(*shortNode); ok {
k := append([]byte{byte(pos)}, cnode.Key...)
return true, &shortNode{k, cnode.Val, t.newFlag()}, nil
}
}
return true, &shortNode{[]byte{byte(pos)}, n.Children[pos], t.newFlag()}, nil
}
return true, n, nil
case valueNode:
return true, nil, nil
case nil:
return false, nil, nil
case hashNode:
rn, err := t.resolveHash(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.delete(rn, prefix, key)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v (%v)", n, n, key))
}
}参数和返回值和插入操作类似,不在赘述。依旧是判断当前节点类型:
- 若为shortNode结点,首先也是计算公共前缀。若公共前缀的长度小于当前节点key的长度,表示没有匹配到。若公共前缀的长度等于要删除的key的长度,表示匹配到子树,直接删除该节点为根的子树。若公共前缀的长度等于当前节点key的长度,也就是当前节点的key是要删除key的一部分,说明还要向下查找。但是删除完后要对节点做处理,若子节点fullnode节点删除孩子后孩子数量大于1个,则只改变当前节点的flag。若删除后孩子数量小于等于一个,则要对节点进行合并,也就是对前缀进行合并
- 若为fullnode结点,则直接根据key的第一个字符取尝试删除某个孩子。然后遍历孩子,判断非空的数量,若大于两个则不做处理,若只有一个,进行节点的合并。
- 若为valueNode节点,直接删除,返回
- 若为nil,一般在阐述fullnode的孩子时遇到,表示没有匹配,不做处理
- 若为hashNode,表示还在数据库中,则先加载,在尝试删除
查询
也就是Get方法,见代码:
func (t *Trie) Get(key []byte) []byte {
res, err := t.TryGet(key)
if err != nil {
log.Error(fmt.Sprintf("Unhandled trie error: %v", err))
}
return res
}
func (t *Trie) TryGet(key []byte) ([]byte, error) {
key = keybytesToHex(key) //转为16进制半字节
value, newroot, didResolve, err := t.tryGet(t.root, key, 0)
if err == nil && didResolve {
t.root = newroot
}
return value, err
}
func (t *Trie) tryGet(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if len(key)-pos < len(n.Key) || !bytes.Equal(n.Key, key[pos:pos+len(n.Key)]) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.tryGet(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n = n.copy()
n.Val = newnode
n.flags.gen = t.cachegen
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.tryGet(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n = n.copy()
n.flags.gen = t.cachegen
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveHash(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.tryGet(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}查找的逻辑也很简单,首先要把byte数组转为16进制半字节的数组形式,使用keybytesToHex方法(后面会讲)。之后从根节点开始,调用tryGet递归查询,也分一下几种情况:
- 若为空,表示没有找到
- 若为valueNode节点,直接返回即可
- 若为shortNode,如果当前节点的key长度大于本次递归要查找的或即使长度相等但内容不一样的,则表示没有匹配的,否则继续递归查找
- 若为fullNode结点,则递归到孩子中寻找
- 若为hashNode结点,则先从数据库中加载,在尝试递归查询
编码
主要是encoding.go,处理树的三种编码格式的互相转换。
- keybytes:原始字节数组,大部分trie的函数都用这种格式
- hex:hex编码,将一个字节用两个字节表示,编码时,将8位二进制码重新分组成两个4位的字节,其中一个字节的低4位是原字节的高四位,另一个字节的低4位是原数据的低4位,高4位都补0。编码后再在尾部跟上一个标志位0x10,标识是叶子节点或者扩展节点
- compact:compact编码,就是Hex-Prefix Encoding,在黄皮书中的附录C有说明。是hex编码的变体。第一个字节的高位存储标志位,低位存储0(长度为偶数)或hex编码的第一个半字节(长度为奇数)。总之最后长度是偶数。数学描述如下(f(t)表示hex编码的标志位是否存在):
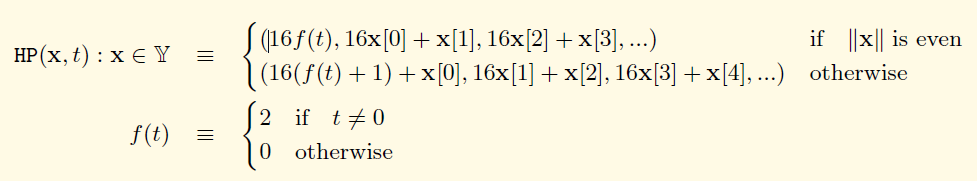
下面具体看源码:
hexToCompact
hex编码转compact编码
func hexToCompact(hex []byte) []byte {
terminator := byte(0)
if hasTerm(hex) {
terminator = 1
hex = hex[:len(hex)-1]
}
buf := make([]byte, len(hex)/2+1)
buf[0] = terminator << 5 // the flag byte
if len(hex)&1 == 1 {
buf[0] |= 1 << 4 // odd flag
buf[0] |= hex[0] // first nibble is contained in the first byte
hex = hex[1:]
}
decodeNibbles(hex, buf[1:])
return buf
}hasTerm判断最后一字节是否是16,也就是有没有标志位,若是则terminator标记为1,并去除hex编码的标志位。接下来写入compat编码的标志位,首先terminator右移5位,再判断hex编码长度的奇偶性,并根据情况改下标志位。然后解码hex编码改为compat编码,流程和黄皮书一致。
compactToHex
compact编码转hex编码
func compactToHex(compact []byte) []byte {
if len(compact) == 0 {
return compact
}
base := keybytesToHex(compact)
// delete terminator flag
if base[0] < 2 {
base = base[:len(base)-1]
}
// apply odd flag
chop := 2 - base[0]&1
return base[chop:]
}可见先看做一般字节数组,然后转为hex编码。然后判断是否有标志位。首先根据黄皮书规定,compact编码的第一字节的高四位有这几种情况:
0000 hex编码没有标志位,且长度为偶数
0001 hex编码没有标志位,且长度为奇数
0010 hex编码有标志位,且长度为偶数
0011 hex编码有标志位,且长度为奇数根据上面四种情况,删除最后的标志位。然后在根据第一位的值,决定是删除前两位还是第一位
keybytesToHex
原始数组转hex编码
func keybytesToHex(str []byte) []byte {
l := len(str)*2 + 1
var nibbles = make([]byte, l)
for i, b := range str {
nibbles[i*2] = b / 16
nibbles[i*2+1] = b % 16
}
nibbles[l-1] = 16
return nibbles
}很简单,就是一个字节拆为两个字节,利用整除和取余,最后加一个标志位。
hexToKeybytes
hex编码还原
func hexToKeybytes(hex []byte) []byte {
if hasTerm(hex) {
hex = hex[:len(hex)-1]
}
if len(hex)&1 != 0 {
panic("can't convert hex key of odd length")
}
key := make([]byte, len(hex)/2)
decodeNibbles(hex, key)
return key
}
func decodeNibbles(nibbles []byte, bytes []byte) {
for bi, ni := 0, 0; ni < len(nibbles); bi, ni = bi+1, ni+2 {
bytes[bi] = nibbles[ni]<<4 | nibbles[ni+1]
}
}先根据需求去除标志位,再具体转换。可见将两字节还原为一字节时就是利用移位和或逻辑。
序列化
序列化就是将一课树存储到数据库中
// go-ethereum\trie\trie.go
func (t *Trie) Commit(onleaf LeafCallback) (root common.Hash, err error) {
if t.db == nil {
panic("commit called on trie with nil database")
}
hash, cached, err := t.hashRoot(t.db, onleaf)
if err != nil {
return common.Hash{}, err
}
t.root = cached
t.cachegen++
return common.BytesToHash(hash.(hashNode)), nil
}
func (t *Trie) hashRoot(db *Database, onleaf LeafCallback) (node, node, error) {
if t.root == nil {
return hashNode(emptyRoot.Bytes()), nil, nil
}
h := newHasher(t.cachegen, t.cachelimit, onleaf)
defer returnHasherToPool(h)
return h.hash(t.root, db, true)
}这一部分主要是创建了hasher,然后利用hash方法去实现。进入hasher的代码
// go-ethereum\trie\hasher.go
func newHasher(cachegen, cachelimit uint16, onleaf LeafCallback) *hasher {
h := hasherPool.Get().(*hasher)
h.cachegen, h.cachelimit, h.onleaf = cachegen, cachelimit, onleaf
return h
}hasherPool是一个对象池,newHasher方法主要是从中尝试取或者创建一个hasher对象。下面看hash方法:
func (h *hasher) hash(n node, db *Database, force bool) (node, node, error) {
if hash, dirty := n.cache(); hash != nil {
if db == nil {
return hash, n, nil
}
if n.canUnload(h.cachegen, h.cachelimit) {
cacheUnloadCounter.Inc(1)
return hash, hash, nil
}
if !dirty {
return hash, n, nil
}
}
collapsed, cached, err := h.hashChildren(n, db)
if err != nil {
return hashNode{}, n, err
}
hashed, err := h.store(collapsed, db, force)
if err != nil {
return hashNode{}, n, err
}
cachedHash, _ := hashed.(hashNode)
switch cn := cached.(type) {
case *shortNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
case *fullNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
}
return hashed, cached, nil
}第一个if我们后面再解释,接下来的hashChildren是一个关键点,它将所有的子节点换为他们的hash
func (h *hasher) hashChildren(original node, db *Database) (node, node, error) {
var err error
switch n := original.(type) {
case *shortNode:
collapsed, cached := n.copy(), n.copy()
collapsed.Key = hexToCompact(n.Key)
cached.Key = common.CopyBytes(n.Key)
if _, ok := n.Val.(valueNode); !ok {
collapsed.Val, cached.Val, err = h.hash(n.Val, db, false)
if err != nil {
return original, original, err
}
}
return collapsed, cached, nil
case *fullNode: subtrees
collapsed, cached := n.copy(), n.copy()
for i := 0; i < 16; i++ {
if n.Children[i] != nil {
collapsed.Children[i], cached.Children[i], err = h.hash(n.Children[i], db, false)
if err != nil {
return original, original, err
}
}
}
cached.Children[16] = n.Children[16]
return collapsed, cached, nil
default:
return n, original, nil
}
}主要也是根据结点类型进行操作。
- 对于shortNode节点,先对key从hex编码转为compact编码,然后递归调用hash把子节点也改为hash
- 对于fullNode结点,遍历所有孩子,递归调用hash方法
- 对于其他类型节点原样返回
再回到hash方法,接下来调用store方法。
func (h *hasher) store(n node, db *Database, force bool) (node, error) {
if _, isHash := n.(hashNode); n == nil || isHash {
return n, nil
}
h.tmp.Reset()
if err := rlp.Encode(&h.tmp, n); err != nil {
panic("encode error: " + err.Error())
}
if len(h.tmp) < 32 && !force {
return n, nil // Nodes smaller than 32 bytes are stored inside their parent
} database.
hash, _ := n.cache()
if hash == nil {
hash = h.makeHashNode(h.tmp)
}
if db != nil { cache
hash := common.BytesToHash(hash)
db.lock.Lock()
db.insert(hash, h.tmp, n)
db.lock.Unlock()
if h.onleaf != nil {
switch n := n.(type) {
case *shortNode:
if child, ok := n.Val.(valueNode); ok {
h.onleaf(child, hash)
}
case *fullNode:
for i := 0; i < 16; i++ {
if child, ok := n.Children[i].(valueNode); ok {
h.onleaf(child, hash)
}
}
}
}
}
return hash, nil
}首先判断节点类型,若本身就是hashNode或为空不存储。然后对节点编码。详细流程不在赘述,参考RLP编码学习。编码之后的结果存在tmp这个字节数组中。接下来判断是否强制存储,然后计算根节点编码后结果hash,最后存储到数据库,键就是刚才计算的hash。
再次回到hash方法,存储成功后。将存储的键转为hashNode类,然后判断cached(实际是跟节点的copy)的类型,对于是shortNode和fullNode类型,将其flags成员的hash值进行修改,然后返回hash值和cached。
反序列化
不同于序列化,反序列化在trie的源码中就多次出现,主要是下面方法
func (t *Trie) resolveHash(n hashNode, prefix []byte) (node, error) {
cacheMissCounter.Inc(1)
hash := common.BytesToHash(n)
if node := t.db.node(hash, t.cachegen); node != nil {
return node, nil
}
return nil, &MissingNodeError{NodeHash: hash, Path: prefix}
}主要逻辑在node方法中
// go-ethereum\trie\database.go
func (db *Database) node(hash common.Hash, cachegen uint16) node {
if db.cleans != nil {
if enc, err := db.cleans.Get(string(hash[:])); err == nil && enc != nil {
memcacheCleanHitMeter.Mark(1)
memcacheCleanReadMeter.Mark(int64(len(enc)))
return mustDecodeNode(hash[:], enc, cachegen)
}
}
db.lock.RLock()
dirty := db.dirties[hash]
db.lock.RUnlock()
if dirty != nil {
return dirty.obj(hash, cachegen)
}
enc, err := db.diskdb.Get(hash[:])
if err != nil || enc == nil {
return nil
}
if db.cleans != nil {
db.cleans.Set(string(hash[:]), enc)
memcacheCleanMissMeter.Mark(1)
memcacheCleanWriteMeter.Mark(int64(len(enc)))
}
return mustDecodeNode(hash[:], enc, cachegen)
}这也是一个典型的二级缓存的例子,首先尝试从内存缓存中获取,若没有,则从磁盘的数据库中获取,最后实际反序列化操作都在mustDecodeNode方法中
// go-ethereum\trie\node.go
func mustDecodeNode(hash, buf []byte, cachegen uint16) node {
n, err := decodeNode(hash, buf, cachegen)
if err != nil {
panic(fmt.Sprintf("node %x: %v", hash, err))
}
return n
}
func decodeNode(hash, buf []byte, cachegen uint16) (node, error) {
if len(buf) == 0 {
return nil, io.ErrUnexpectedEOF
}
elems, _, err := rlp.SplitList(buf)
if err != nil {
return nil, fmt.Errorf("decode error: %v", err)
}
switch c, _ := rlp.CountValues(elems); c {
case 2:
n, err := decodeShort(hash, elems, cachegen)
return n, wrapError(err, "short")
case 17:
n, err := decodeFull(hash, elems, cachegen)
return n, wrapError(err, "full")
default:
return nil, fmt.Errorf("invalid number of list elements: %v", c)
}
}首先解释一下涉及到的几个rlp方法,通过学习rlp编码我们知道,rlp编码一般由一个标志位+前缀+内容组成,SplitList方法返回的就是内容以及剩余内容(未被解析的)。对于复合类型,也就是编码中的第二种数据来源–多维数组类型,它的rlp编码内容部分是由多个单独的子类型rlp编码组合而成的,CountValues就是统计有多少个子部分。
接下来一个switch就是根据有多少子内容区分节点的类型,如代码中所述,2个子内容的就是shortNode,17个的就是fullNode,注意这点可能会有些人有疑问,我们定义节点的时候,这两类节点可不止这几个成员变量,这是因为在存储时节点都被转化为rawShortNode和rawFullNode两种简单类型( go-ethereum\trie\database.go),只保留关键信息。我们接下来再看具体的反序列化方法
func decodeShort(hash, elems []byte, cachegen uint16) (node, error) {
kbuf, rest, err := rlp.SplitString(elems)
if err != nil {
return nil, err
}
flag := nodeFlag{hash: hash, gen: cachegen}
key := compactToHex(kbuf)
if hasTerm(key) {
val, _, err := rlp.SplitString(rest)
if err != nil {
return nil, fmt.Errorf("invalid value node: %v", err)
}
return &shortNode{key, append(valueNode{}, val...), flag}, nil
}
r, _, err := decodeRef(rest, cachegen)
if err != nil {
return nil, wrapError(err, "val")
}
return &shortNode{key, r, flag}, nil
}
func decodeRef(buf []byte, cachegen uint16) (node, []byte, error) {
kind, val, rest, err := rlp.Split(buf)
if err != nil {
return nil, buf, err
}
switch {
case kind == rlp.List:
if size := len(buf) - len(rest); size > hashLen {
err := fmt.Errorf("oversized embedded node (size is %d bytes, want size < %d)", size, hashLen)
return nil, buf, err
}
n, err := decodeNode(nil, buf, cachegen)
return n, rest, err
case kind == rlp.String && len(val) == 0:
return nil, rest, nil
case kind == rlp.String && len(val) == 32:
return append(hashNode{}, val...), rest, nil
default:
return nil, nil, fmt.Errorf("invalid RLP string size %d (want 0 or 32)", len(val))
}
}逻辑还是很清晰的,首先使用SplitString,分理处内容和剩余数据,然后将内容转为hex编码,再判断value是否有标志位来决定是否是叶子节点,若是叶子节点,则解析剩余的内容。若不是,则使用decodeRef来解析剩余内容。decodeRef首先也是分离出rlp编码各部分,先判断类型,再根据类型生成具体的节点。最后回到decodeShort构造出一个完整的节点。另外decodeFull流程也类似,不在赘述。主要思想就是一层一层剥开rlp编码,根据具体类型生成具体节点。
trie的cache
trie除了有数据库和根节点这两个成员变量,还有cachegen, cachelimit用于缓存管理的变量。trie树在每次commit时都会将cachegen加1(见上面序列化部分源码),然后在每次插入节点时都会把cachegen写入新节点,利用的是newFlag方法
func (t *Trie) newFlag() nodeFlag {
return nodeFlag{dirty: true, gen: t.cachegen}
}当trie.cachegen - node.cachegen > cachelimit时,就会把节点从内存中卸载(删除),用的是canUnload方法判断,每个继承node接口的类都实现了该方法:
func (n *fullNode) canUnload(gen, limit uint16) bool { return n.flags.canUnload(gen, limit) }
func (n *shortNode) canUnload(gen, limit uint16) bool { return n.flags.canUnload(gen, limit) }
func (n hashNode) canUnload(uint16, uint16) bool { return false }
func (n valueNode) canUnload(uint16, uint16) bool { return false }卸载的作用是节省内存,所以说经过几次commit后,就会有节点被从内存中删除,删除是在hash方法中,也就是那个方法的第一个if
func (h *hasher) hash(n node, db *Database, force bool) (node, node, error) {
if hash, dirty := n.cache(); hash != nil {
if db == nil {
return hash, n, nil
}
if n.canUnload(h.cachegen, h.cachelimit) {
cacheUnloadCounter.Inc(1)
return hash, hash, nil
}
if !dirty {
return hash, n, nil
}
}
....获取hash是首先从节点的cache中获取,若存在的话,先不急着返回,首先判断是否可卸载,若可以,则卸载,注意卸载方式很有意思,不返回节点实例,而是返回一个hash表示节点,然后需要的时候在反序列化即可。注意若节点没有缓存hash值,则一定不进行卸载。
SecureTrie
最后还有一个SecureTrie,是为了避免使用很长的key导致性能下降。SecureTrie包装了trie,所有的key都转化为keccak256计算的hash,但在数据库中存储原始key
type SecureTrie struct {
trie Trie
hashKeyBuf [common.HashLength]byte
secKeyCache map[string][]byte //hash值和key值的映射
secKeyCacheOwner *SecureTrie
}database.go
这也是trie包中的,是比较贴近实际使用的。源码注释中介绍它是一个介于内存中的trie数据和硬盘的中间层,作用是不将每次树的操作都写入内存,而是周期性的写入。
先看初始化,在其他地方源码中用的较多的是NewDatabase与NewDatabaseWithCache两个方法,均可以获得一个database对象
func NewDatabase(diskdb ethdb.Database) *Database {
return NewDatabaseWithCache(diskdb, 0)
}
func NewDatabaseWithCache(diskdb ethdb.Database, cache int) *Database {
var cleans *bigcache.BigCache
if cache > 0 {
cleans, _ = bigcache.NewBigCache(bigcache.Config{
Shards: 1024,
LifeWindow: time.Hour,
MaxEntriesInWindow: cache * 1024,
MaxEntrySize: 512,
HardMaxCacheSize: cache,
})
}
return &Database{
diskdb: diskdb,
cleans: cleans,
dirties: map[common.Hash]*cachedNode{{}: {}},
preimages: make(map[common.Hash][]byte),
}
}通过参考BlockChain源码我们可以知道,为了获得一个statedb对象,会使用statedb.New方法,其中需要一个Database对象,一般都是通过state包中的NewDatabase或者NewDatabaseWithCache方法,但是需要一个参数,所以由调用了trie包中的NewDatabase或者NewDatabaseWithCache方法,如下:
state, err := state.New(parent.Root(), bc.stateCache)
stateCache: state.NewDatabaseWithCache(db, cacheConfig.TrieCleanLimit),
func NewDatabaseWithCache(db ethdb.Database, cache int) Database {
csc, _ := lru.New(codeSizeCacheSize)
return &cachingDB{
db: trie.NewDatabaseWithCache(db, cache),
codeSizeCache: csc,
}
}通过层层引用,只有到trie包中的database对象才持有真正的数据库对象。
InsertBlob
这个方法出现在statedb的commit中,如果一个stateObject的code字段不为空且被设置过,则将code进行插入
s.db.TrieDB().InsertBlob(common.BytesToHash(stateObject.CodeHash()), stateObject.code)
func (db *Database) InsertBlob(hash common.Hash, blob []byte) {
db.lock.Lock()
defer db.lock.Unlock()
db.insert(hash, blob, rawNode(blob))
}
func (db *Database) insert(hash common.Hash, blob []byte, node node) {
if _, ok := db.dirties[hash]; ok {
return
}
entry := &cachedNode{
node: simplifyNode(node),
size: uint16(len(blob)),
flushPrev: db.newest,
}
for _, child := range entry.childs() {
if c := db.dirties[child]; c != nil {
c.parents++
}
}
db.dirties[hash] = entry
if db.oldest == (common.Hash{}) {
db.oldest, db.newest = hash, hash
} else {
db.dirties[db.newest].flushNext, db.newest = hash, hash
}
db.dirtiesSize += common.StorageSize(common.HashLength + entry.size)
}InsertBlob我们传入要存储的数据及其hash,之后调用insert方法,将要传入的数据又包装成一个rawNode类型。在insert方法中,首先检测要传入的数据是否被缓存过,是的话直接结束操作。
之后构建了一个cacheNode类型。然后调用了childs遍历其所有孩子并将其组成一个Hash类型的数组,之后遍历这个数组,看是否有引入该节点的项,有的话将其对应的parents字段加一。最后将刚才生成的cacheNode放入dirties中。
再往下有一个修改oldest与newest的逻辑,这里解释一下,源码这这里构建了一个刷新列表,实际为一个链表,oldest表示列表中最旧的节点,在列表头部;newest表示最新的节点,位于列表尾部。而cachedNode的flushNext表示该节点之后下一个要刷入数据库的节点,对应的还有flushPrev,在构造cachedNode时被设为newest。这里,如果oldest为空,表示列表为空,则oldest与newest都为当前该节点。否则只修改newest和该节点的flushNext字段。
接着修改database的dirtiesSize表示已缓存的数据量。
Commit
可以看到之前的insert方法并没有将数据存入数据库,而是放入dirties中,我们这里看一下commit方法,他要求传入一个节点hash:
func (db *Database) Commit(node common.Hash, report bool) error {
db.lock.RLock()
start := time.Now()
batch := db.diskdb.NewBatch()
for hash, preimage := range db.preimages {
if err := batch.Put(db.secureKey(hash[:]), preimage); err != nil {
log.Error("Failed to commit preimage from trie database", "err", err)
db.lock.RUnlock()
return err
}
if batch.ValueSize() > ethdb.IdealBatchSize {
if err := batch.Write(); err != nil {
db.lock.RUnlock()
return err
}
batch.Reset()
}
}
nodes, storage := len(db.dirties), db.dirtiesSize
if err := db.commit(node, batch); err != nil {
log.Error("Failed to commit trie from trie database", "err", err)
db.lock.RUnlock()
return err
}
if err := batch.Write(); err != nil {
log.Error("Failed to write trie to disk", "err", err)
db.lock.RUnlock()
return err
}
db.lock.RUnlock()
db.lock.Lock()
defer db.lock.Unlock()
db.preimages = make(map[common.Hash][]byte)
db.preimagesSize = 0
db.uncache(node)
memcacheCommitTimeTimer.Update(time.Since(start))
memcacheCommitSizeMeter.Mark(int64(storage - db.dirtiesSize))
memcacheCommitNodesMeter.Mark(int64(nodes - len(db.dirties)))
logger := log.Info
if !report {
logger = log.Debug
}
logger("Persisted trie from memory database", "nodes", nodes-len(db.dirties)+int(db.flushnodes), "size", storage-db.dirtiesSize+db.flushsize, "time", time.Since(start)+db.flushtime,
"gcnodes", db.gcnodes, "gcsize", db.gcsize, "gctime", db.gctime, "livenodes", len(db.dirties), "livesize", db.dirtiesSize)
db.gcnodes, db.gcsize, db.gctime = 0, 0, 0
db.flushnodes, db.flushsize, db.flushtime = 0, 0, 0
return nil
}这里首先创建了一个数据库的batch对象,用于后面批量操作。首先放入batch中的是preimages数据,这个稍后再说。每放入一个就检查是否超过batch规定的最大容量(100KB),超过的话先执行一次写入操作再进行后续的数据放入。在往下调用了commit方法:
func (db *Database) commit(hash common.Hash, batch ethdb.Batch) error {
node, ok := db.dirties[hash]
if !ok {
return nil
}
for _, child := range node.childs() {
if err := db.commit(child, batch); err != nil {
return err
}
}
if err := batch.Put(hash[:], node.rlp()); err != nil {
return err
}
if batch.ValueSize() >= ethdb.IdealBatchSize {
if err := batch.Write(); err != nil {
return err
}
batch.Reset()
}
return nil
}这个方法很简单就是从指定的节点开始递归遍历节点的所有孩子,将节点经过rlp编码后存入数据库。回到Commit中,调用了一次batch的write方法确保所有数据都被写入数据库。最后初始化一些变量。
Reference
func (db *Database) Reference(child common.Hash, parent common.Hash) {
db.lock.RLock()
defer db.lock.RUnlock()
db.reference(child, parent)
}
func (db *Database) reference(child common.Hash, parent common.Hash) {
node, ok := db.dirties[child]
if !ok {
return
}
if db.dirties[parent].children == nil {
db.dirties[parent].children = make(map[common.Hash]uint16)
} else if _, ok = db.dirties[parent].children[child]; ok && parent != (common.Hash{}) {
return
}
node.parents++
db.dirties[parent].children[child]++
}Reference是建立一个从父结点到子节点的引用。首先检查了是否缓存有子节点,有的话再看要建立引入的父节点的孩子是否为空,再检查是否已经建立的引用,没有的将孩子节点的父节点树加一,然后将父节点对应的孩子节点引用树加一。
Cap
这个方法在BlockChain中实际写入一个区块后,如果是带缓存模式时,先检查已缓存是否超过的现在,超过的话利用此方法写入数据库
func (db *Database) Cap(limit common.StorageSize) error {
db.lock.RLock()
nodes, storage, start := len(db.dirties), db.dirtiesSize, time.Now()
batch := db.diskdb.NewBatch()
size := db.dirtiesSize + common.StorageSize((len(db.dirties)-1)*2*common.HashLength)
flushPreimages := db.preimagesSize > 4*1024*1024
if flushPreimages {
for hash, preimage := range db.preimages {
if err := batch.Put(db.secureKey(hash[:]), preimage); err != nil {
log.Error("Failed to commit preimage from trie database", "err", err)
db.lock.RUnlock()
return err
}
if batch.ValueSize() > ethdb.IdealBatchSize {
if err := batch.Write(); err != nil {
db.lock.RUnlock()
return err
}
batch.Reset()
}
}
}
oldest := db.oldest
for size > limit && oldest != (common.Hash{}) {
node := db.dirties[oldest]
if err := batch.Put(oldest[:], node.rlp()); err != nil {
db.lock.RUnlock()
return err
}
if batch.ValueSize() >= ethdb.IdealBatchSize {
if err := batch.Write(); err != nil {
log.Error("Failed to write flush list to disk", "err", err)
db.lock.RUnlock()
return err
}
batch.Reset()
}
size -= common.StorageSize(3*common.HashLength + int(node.size))
oldest = node.flushNext
}
if err := batch.Write(); err != nil {
log.Error("Failed to write flush list to disk", "err", err)
db.lock.RUnlock()
return err
}
db.lock.RUnlock()
db.lock.Lock()
defer db.lock.Unlock()
if flushPreimages {
db.preimages = make(map[common.Hash][]byte)
db.preimagesSize = 0
}
for db.oldest != oldest {
node := db.dirties[db.oldest]
delete(db.dirties, db.oldest)
db.oldest = node.flushNext
db.dirtiesSize -= common.StorageSize(common.HashLength + int(node.size))
}
if db.oldest != (common.Hash{}) {
db.dirties[db.oldest].flushPrev = common.Hash{}
}
db.flushnodes += uint64(nodes - len(db.dirties))
db.flushsize += storage - db.dirtiesSize
db.flushtime += time.Since(start)
memcacheFlushTimeTimer.Update(time.Since(start))
memcacheFlushSizeMeter.Mark(int64(storage - db.dirtiesSize))
memcacheFlushNodesMeter.Mark(int64(nodes - len(db.dirties)))
log.Debug("Persisted nodes from memory database", "nodes", nodes-len(db.dirties), "size", storage-db.dirtiesSize, "time", time.Since(start),
"flushnodes", db.flushnodes, "flushsize", db.flushsize, "flushtime", db.flushtime, "livenodes", len(db.dirties), "livesize", db.dirtiesSize)
return nil
}同样先获取了batch,然后计算了几个数据:dirties的长度,dirties内容大小以及总的大小(包含dirties的内容大小dirties自身大小)。接着判断了preimages是否超过了4MB,超过的话将其写入数据库。
接着获取要刷入列表的头部,也就是oldest指向的节点。此时如果刚才计算的总大小超过了限制,则从oldest开始,沿着那个刷新链表将每个节点写入数据库,直到链表结束或总的大小不超过限制为止。接着又调用了一次Write方法确保数据被写入数据库。最后更新了几个变量。
Preimage
这个和SecureTrie有关,每当SecureTrie利用Update或TryUpdate向树中插入数据时,都会将要存储的键值对在secKeyCache从缓存一份,在SecureTrie的的commit方法中,在调用trie的commit之前,secKeyCache中的数据通过insertPreimage插入
func (db *Database) insertPreimage(hash common.Hash, preimage []byte) {
if _, ok := db.preimages[hash]; ok {
return
}
db.preimages[hash] = common.CopyBytes(preimage)
db.preimagesSize += common.StorageSize(common.HashLength + len(preimage))
}secKeyCache表示一个树的阶段性状态,在调用commit后会对secKeyCache清空。
在database中提交时,无论是调用commit或者cap方法,都是先提交preimages,在提交节点数据。其中preimages实际上相当于存储着树中的原始数据,而存储节点时而存储的是节点(指cachedNode)rlp编码后的数据。
题图来自unsplash:https://unsplash.com/photos/hnw3Al47-KE