Protobuf学习及编码深入
简介
按照官方的介绍,Protocol buffers是一种与具体平台或者编程语言无关的可扩展的序列化语言,类似于XML或者JSON,由其对比XML而言,具有更小更快更简单的特点。接下来我们就来了解一下这个东西。
简单使用
一般而言,使用步骤有三步。首先定义Protobuf模板文件,以.proto为后缀;然后生成特定语言的接口代码;最后利用接口代码进行序列化或者反序列操作。整体步骤和我们利用一些第三方库如Gson去操作json文件类似,下面就具体看一下这几个过程:
定义Protobuf文件
下面这个例子是官方文档给出,定义了一个地址簿的数据结构:
syntax = "proto2";
package tutorial;
option java_package = "code.protobuf";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}
message AddressBook {
repeated Person people = 1;
}具体语法我们稍后再介绍,首先可以看到,Protobuf文件的格式很像一些面向对象语言中类的定义,上面例子一个message就像一个类定义,类之间可以嵌套。AddressBook中有Person对象,Person中又有PhoneNumber对象。Person中也有一些基本类型如string和int。用过Gson之类的库解析json的应该感觉这和解析json时定义的类很像。
编译
写好Protobuf文件后,就相当于写好一个模板文件,在不同平台或者不同语言间交互时都以这个文件为标准,但是还不能直接,根据具体的编程语言,我们还要有接口文件,我们可以利用官方给的编译工具生成我们需要的接口代码,以java语言为例:
protoc --java_out=src\ src\code\protobuf\addressbook.proto–java_out表示生成的接口文件路径,由于我们在Protobuf文件文件中定义了java_package,所以只需指定包所在目录即可,生成的文件会自动放在具体包下,最后指定Protobuf文件具体路径。生成的文件名在Protobuf文件中java_outer_classname字段定义。
接口操作
执行完命令后,在code.protobuf包下生成了AddressBookProtos.java文件(要使用这个代码还需要导入相关库)。代码还是很长的,我们仅仅定义了一个简单的地址簿数据结构,就生成了近2000行代码,但是对于我们所使用的接口而言,生成的这个代码其实就是一个JavaBean类,它使用了建造者模式,当我们要构造一个Person对象时,如下:
AddressBookProtos.Person john = AddressBookProtos.Person.newBuilder().setId(1234)
.setName("John")
.setEmail("john@163.com")
.addPhones(AddressBookProtos.Person.PhoneNumber.newBuilder()
.setNumber("15463")
.setType(AddressBookProtos.Person.PhoneType.HOME)
.build())
.build();除了常用的get与set方法,还提供了:toString()方法用于转为有意义的字符串形式;isInitialized()方法用于检测所有必需字段是否设置;clear()方法用于清空所有字段;mergeFrom(Message other)用于合并两个对象。
当然作为序列化工具,生成的对象也提供了序列化和反序列化相关的方法:toByteArray()和parseFrom(byte[] data)。另外还可以直接操作流:writeTo(OutputStream output)和parseFrom(InputStream input)。
简单示例
这里演示一个简单的跨语言的传输数据的例子。使用Go语言编写服务端,java编写客户端,从客户端向服务端发送数据。protobuf文件还使用上面的例子,这里在使用编译工具编译go语言的接口文件,protobuf文件不用做任何修改:
protoc --go_out=.\ src\code\protobuf\addressbook.protojava的客户端代码如下:
public static void main(String[] args) {
AddressBookProtos.Person person = AddressBookProtos.Person.newBuilder()
.setName("jack")
.setId(1)
.setEmail("jack@163.com")
.build();
AddressBookProtos.AddressBook book = AddressBookProtos.AddressBook.newBuilder()
.addPeople(person)
.build();
try (Socket socket = new Socket("127.0.0.1",1234)){
OutputStream out = socket.getOutputStream();
out.write(book.toByteArray());
socket.shutdownOutput();
} catch (Exception e) {
e.printStackTrace();
}
}go的服务端代码如下
func main() {
listener,err:=net.Listen("tcp",":1234")
if err!=nil{
log.Fatalln("Listen:",err.Error())
}
con,err:=listener.Accept()
if err!=nil{
log.Fatalln("Accept:",err.Error())
}
result,err:=ioutil.ReadAll(con)
if err!=nil{
log.Fatalln("ReadAll:",err.Error())
}
book := &tutorial.AddressBook{}
if err := proto.Unmarshal(result, book); err != nil {
log.Fatalln("Failed to parse address book:", err)
}
fmt.Println(*book.People[0].Email)
}详细语法
首先在文件第一行在指定语法版本,如:syntax = “proto2”;
基本字段类型
message中每个字段都要指定数据类型。如下表:
分配字段编号
如例子中所示,每个字段都要分配一个独一无二编号,编号范围在1~536,870,911,主要是为了标记字段,并且不能改变,需要注意的是19000到19999是不能使用的。关于编号,官方文档建议,对于频繁使用的元素应当使用1到15的编号,因为这些序号被编码为1byte,而16到2047被编码为2byte。
字段约束
有以下几个修饰词:
required:使用时必须被指定的字段
optional:可以不被指定,但是最多只能指定一个
repeated:可以出现次的,也可以不出现,相当于数组的概念。官方建议使用[packed=true]选项提高编码效率:repeated int32 samples = 4 [packed=true];了解完字段类型,编号,约束词以后,我们可以得到message中一个字段的完整定义:
字段约束 类型 名称 = 字段编号;
required string query = 1;注释
类似于java等语言的注释风格:使用// 或/**/
保留字
对于以删除的字段,若是后面再被使用,可能会导致问题,所以可以用reserved标记出来,若被使用编译器将报错。reserved使用方法如下:
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}注意字段和编号不能混合在一起用reserved标记
可选字段的默认值
对于optional修饰的字段,若未定义,会有一个与字段类型对应的默认值,如string为空,bool为false等,我们也可以指定默认值如下所示:
optional int32 result_per_page = 3 [default = 10];枚举类型
定义如下:
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}在一个枚举中,可以指定一些相同值的成员,这样会被解析为别名,同时需要加上option allow_alias = true
enum EnumAllowingAlias {
option allow_alias = true;
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}若在一个message中使用另一个message的enum可以以MessageType.EnumType的形式调用
导包
protobuf也有导包的概念,如果要从一个proto文件中引用另一个proto文件中的一个message,需要使用import关键字进行导包。注意在编译时使用-I指定搜索包的路径,否则只会默认搜索当前目录下的文件
嵌套定义
message SearchResponse {
message Result {
required string url = 1;
optional string title = 2;
repeated string snippets = 3;
}
repeated Result result = 1;
}上面例子在一个message中定义了另一个message,使用时利用SearchResponse.Result引用内部定义的message
Extensions
扩展实际上是一个占位符,它代表未在原始文件中定义的字段
message Foo {
extensions 100 to 199;
}其他用户可以使用extensions指定的字段为原来的message添加新字段
extend Foo {
optional int32 bar = 126;
}访问extension也有特殊的api,示例:
//序列化
AddressBookProtos.AddressBook book = AddressBookProtos.AddressBook.newBuilder()
.setExtension(AddressBookProtos.bar,10)
.build();
byte[] out = book.toByteArray();
//反序列化
ExtensionRegistry registry = ExtensionRegistry.newInstance();
registry.add(AddressBookProtos.bar);
AddressBookProtos.AddressBook ob = AddressBookProtos.AddressBook.parseFrom(out,registry);
System.out.println(ob.hasExtension(AddressBookProtos.bar));注意在反序列化时候要注册需要解析的extension,并作为参数传入parseFrom
Oneof
oneof的出现是为了实现这样的需求:一个message中有多个成员,但同一时间只能有一个成员被赋值。
oneof test{
string a = 4;
string b = 5;
string c = 6;
}AddressBookProtos.Person p2 = AddressBookProtos.Person.newBuilder()
.setName("tom")
.setId(2)
.setEmail("tom@163.com")
.setA("hello")
.setB("world")
.build();
AddressBookProtos.AddressBook book = AddressBookProtos.AddressBook.newBuilder()
.addPeople(p2)
.build();
byte[] out = book.toByteArray();
AddressBookProtos.AddressBook ob = AddressBookProtos.AddressBook.parseFrom(out);
System.out.println(ob.getPeople(0).hasA());
System.out.println(ob.getPeople(0).hasB());可见我们虽然同时对A,B都进行了赋值,但是只有B被赋值成功,也就是同时只有一个成员可以被赋值
需要有以下几点注意:
- 对一个成员赋值,会自动清除其他已赋值的成员
- extension不支持oneof
- oneof不能被修饰为repeated
实际上对于oneof修饰的一组成员,完全可以把它们当做普通的optional成员看待,只不过这几个成员之间又互相依赖关系
另外,oneof:
- 安全的移除或添加字段,但会可能会导致数据丢失
- 可以删除一个oneof,也可能会导致数据丢失
- 可以分割或合并oneof,效果类似移除或添加字段
maps
一般意义上的映射数据类型。
map<string, Project> projects = 3;key可以使任何整数或string(也就是浮点和字节类型除外),枚举也不能做为key。value可以是除map外的任何类型。注意事项:
- extension不支持map
- map不能有repeated, optional, 或 required修饰
- map是无序的
map等效于下面的实现:
message MapFieldEntry {
optional key_type key = 1;
optional value_type value = 2;
}
repeated MapFieldEntry map_field = N;Message更新
更新需要遵循以下规则
- 不要改变已有字段的编号
- 新字段只能使用optional或repeated修饰。这样也很好理解,旧的代码序列化的数据仍然可以被新代码解析,否则会由于缺少required而报错
- 非required修饰的字段可以被移除,但是注意被删除的字段所使用的编号不能再次使用
- 只要类型或者编号不便,非required字段可以转为extension
- int32, uint32, int64, uint64 和 bool 是可以互相兼容的,也就是可以互相转换
- sint32和sint64彼此兼容,但不和其他整数类型兼容
- string和bytes互相兼容,前提是使用UTF-8编码
- fixed32和sfixed32、fixed64、sfixed64是兼容的
- optional与repeated是兼容的,若输入的是repeated,在解析为optional时,以最后一个输入为主,或合并输入
- 可以改变默认值,但要注意不同版本的protobuf文件的默认不同时会在带来潜在的冲突
- enum 和 int32, uint32, int64, uint64是兼容的
- 将optional改为oneof是安全的
packages
在proto文件中指定package字段来防止名字冲突。在java中,除非指定java_package字段,否则会以package作为包名
自定义选项
- java_package :指定生成的java文件所在的包
- java_outer_classname :指定生成的java文件名
- optimize_for :优化选项,有SPEED, CODE_SIZE, 和 LITE_RUNTIME三种选择。SPEED是默认选项,对代码进行优化。CODE_SIZE可以减小生成代码量,但解析速度会下降,LITE_RUNTIME生成的代码最少,但会失去一些特性
- deprecated:被标记为true的字段表示不再使用:optional int32 old_field = 6 [deprecated=true];
proto3语法
proto3的语法和2有很多相似之处,所以这里只介绍一些不同点
版本号
当然版本号要更改为proto3
syntax = "proto3";修饰词
移除了required修饰词;
所有字段默认都是singular,也就是原来的optional,但是不能显式的指定为singular
repeated被保留了
正常情况下一个message书写如下:
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}默认值
取消了default选项,也就是说默认值只能有系统默认指定,如字符串为空串,bool型为false,数字为0等。还有对于枚举类,默认是编号为0的成员。
枚举类型
必须有一个编号为0的成员来作为其第一个成员。
未知字段
在3.5版本之前,不能被解析的字段会被直接抛弃,但是在3.5版本之后,这种特性又回归到proto2上,即不能被解析的字段仍然会保留到下次序列化的输出中
any
用于替代extensions,不过尚在开发中
编码
Varints规则
protobuf的编码基础是Varints,它是将整数序列化为一个或多个byte的方法。 Varints规则是用每byte的第7位存储值,第8位为标志位,若标志位为1,表示后面还有数据,若为0,表示该byte为最后一个。最后Varints采用小端存储。下面举一个例子:
以整数300为例,300的二进制表示如下:
100101100
按小端存储并每7位一组:
0101100 0000010
再加上标志位,最终表示如下:
10101100 00000010Varints的优点是,由于标志位存在,省去了编码长度的表示,其次越小的数编码越短,但是由于标志位的存在,也牺牲了容量,如4byte实际可用表示数值的只有28位
基本编码规则
我们首先看一下message中每个成员变量的定义
int32 a = 1;有三部分组成,变量类型,变量名和变量序号。其中变量名只是为了帮助我们做识别,在编码时不会写入,仅仅用变量序号作为标识,所以也就有了在更新message时序号不能复用的规则,以及可以安全地添加新成员(没有被识别的会直接跳过)。
在编码中,成员变量是以键值对形式出现的,键有两部分组成:成员序号加上成员类型代码,具体代码如下
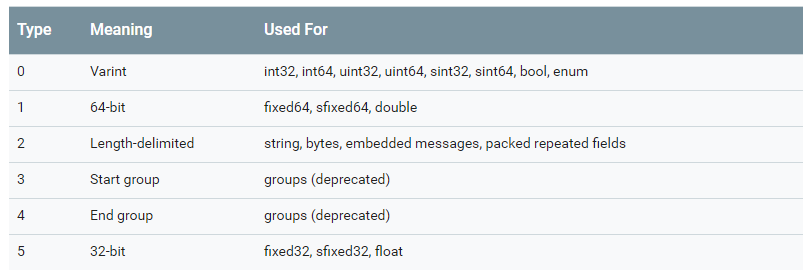
总共有6种代码,其中group使用的两个代码已被弃用,但是依旧保留。这6个代码需要3位二进制表示,所以键的组成是:字段编号+类型代码(加好表示拼接,并不是运算),示例如下:
当我们有一个inst32类型的成员a,编号为1,被赋值为150时
由于是int32类型,根据上图采用varint规则,首先对150进行Varints规则编码(过程略):
10010110 00000001
由于是int32类型,类型代码为0,编号为1,类型代码采用三位二进制表示为000,二者拼接之后如下:
0001000
所以a的最终编码为
0001000 10010110 00000001
改用16进制表示如下
08 96 01其他类型规则
sint32, sint64
对于Varints规则不适用与存储负数,负数最高位为1,造成编码极大的浪费,为了节省空间,引入了ZigZag编码格式,基本思想就是将有符号整数转为无符号整数。转换规则如下:
(n << 1) ^ (n >> 31) #sint32
(n << 1) ^ (n >> 63) #sint64示例如下:
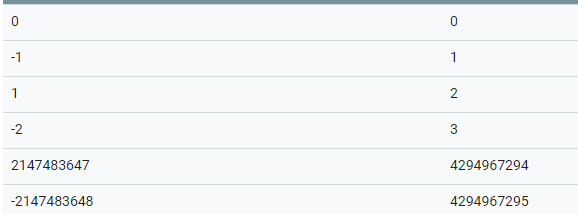
转为无符号的整数后,再用varints编码即可。
64-bit 和 32-bit 类型
这两种分有不同的类型代码,而且编码时不进行其他转换,直接以64位或32位原始存储(注意也是小端存储),读取时根据类型代码直接读取64位或32位
Strings
类型代码2表示一类Length-delimited数据。这种编码类型还附带有长度信息,就是在键值之间附加一个用varints编码的长度编码,例子如下:
我们有一个string类型的变量b,编号为2,赋值为testing
首先testing的utf-8编码如下:
74 65 73 74 69 6e 67
长度为7,varints格式编码如下:
00000111
编号加类型代码拼接后如下:
00010010
最后组合在一起用十六进制表示如下:
12 07 74 65 73 74 69 6e 67除了表示字符串这种简单信息,还可以表示其他message,如下:
message Test3 {
optional Test1 c = 3;
}
其中Test1:
message Test1 {
optional int32 a = 1;
}
我们对Test1中a赋值为150,上面已经计算过,最后编码为
08 96 01
对于Test1类型的变量c表示如下:
首先原始数据就是08 96 01,长度为3,编号为3,类型代码为2,组合起来就是
1a 03 08 96 01packed
在proto3中packed为默认的,在proto2中需要手动指定。使用proto3 模式将会使编码更加紧凑(主要针对repeated 类型)。设想,对于一个repeated类型的成员,他们有多个值时,虽然值不同,前键都是相同的,我们可以减少键的数量,如下例:
假设有一个int32类型的变量d,序号为4,是一个repeated类型,我们赋了4个值,分别是3,270,86942.
使用packed模式后,如下
22 06 03 8E 02 9E A7 05
注意22是编号加类型代码(为2,指packed repeated fields),06表示数据长度
后面实际数据,都是varints编码,但是互有区分顺序
编解码顺序和字段顺序无关,由键值对保证即可。未知字段会写在已知字段后。