rlp编码学习

RLP的全称是Recursive Length Prefix,是以太坊实现中普遍使用的一种序列化方法,在黄皮书的附录B中有详细的定义,我们这里也简要学习一下
源数据
RLP定义了两种源数据,一种是一维的字节数组;另外一种是多维字节数组,也就是一维数组的嵌套。所有要序列化的数据类型,都要有一定的方法转为上述两种格式,转换的方法可以根据不同的实现自己定义。在黄皮书中给出了源数据的定义:
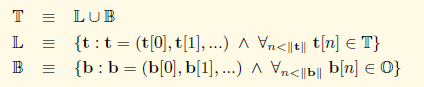
RLP定义
函数定义如下:
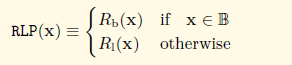
可见分别定义了两个函数,对应了上一节中的两种源数据,分别解释一下这两个函数
源数据为一维字节数组
当数据为简单的一维字节数组时,有以下三种序列化规则:
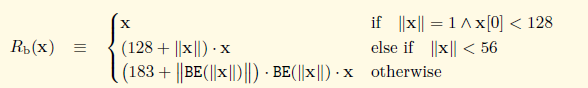
- 当只含有一个字节时,而且这个字节又小于128,则不做任何处理,直接输出,对应上图第一种情况
- 当字节数组的长度小于56时,则加上一个前缀,这个前缀等于128+字节数组长度,对应上图第二种情况
- 若不符合上述两种情况,则加上这样两个前缀,第一个前缀等于183+字节数组长度在大端表示时的长度,第二个前缀为字节数组长度的大端表示,对应上图第三种情况(所谓大端表示就是将高位字节排放在内存的低地址端,0x1234表示为00 00 12 34,BE函数就是去除前面的零,也可以理解为实际长度)
源数据为嵌套的多维字节数组
当数据为嵌套的多维数组形式时,有以下两种序列化规则:
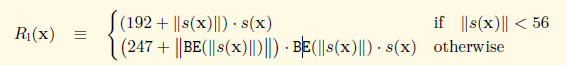
首先对数组中每一个子元素都递归使用上一小节中的规则序列化,注意序列化时对象都要为一维字节数组,若子元素也是嵌套格式,则递归调用,之后将每个子元素序列化结果拼接起来。对于拼接后的长度:
- 若长度小于56,则加上这样一个前缀,这个前缀等于192+拼接后的长度,对应上图第一种情况
- 若长度大于等于56,则加上这样两个前缀,第一个前缀等于247+拼接后字节数组长度在大端表示时的长度,第二个前缀为拼接后的长度的大端表示,对应上图第二种情况
源数据是标量数据
首先RLP只能用于处理正整数,处理是要先用BE函数处理,去掉前导0后,当做字节数组处理,如下图:
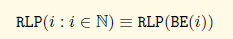
解码
实际上了解到编码规则后,解码就很简单,关键就是第一个字节,这个字节标识使用哪种情况编码
- 当位于[0,128)区间时,对应源数据是一维字节数组的第一种情况,就是单一字节
- 当位于[128,184)区间时,对应源数据是一维字节数组的第二种情况,就是长度小于56的一维字节数组
- 当位于[184,192)区间时,对应源数据是一维字节数组的第三种情况,这时观察第二个前缀,第二个前缀长度等于第一个字节减去183,然后计算原始数据的真正长度
- 当位于[192,247)区间时,对于源数据是多维字节数组的第一种情况,就是拼接长度小于56,递归解析其后数据
- 当位于[247,256)区间时,对于源数据是多维字节数组的第二种情况,类似于第三条规则,先实际计算出第二个前缀的长度,在解析数原始数据长度,在递归解析出原始数据
源码解析
源码主要集中在go-ethereum\rlp目录下,再去除一些测试代码,实际功能代码并不多,关键如下:
decode.go //解码器,就是反序列化
encode.go //编码器,就是序列化
raw.go //未解码的RLP数据
typecache.go //类型缓存, 类型缓存记录了类型->(编码器|解码器)的内容。typecache
由于go-ethereum是用go语言实现的,而go语言没有方法重载,所以对于不同类型的数据要手动指定需要的编解码器。这个类主要功能是给我们返回一个typeinfo类型的对象,这个对象保存在对应数据类型的编解码方法
type typeinfo struct {
decoder
writer
}去创建一个typeinfo需要从cachedTypeInfo方法开始:
// go-ethereum\rlp\typecache.go
func cachedTypeInfo(typ reflect.Type, tags tags) (*typeinfo, error) {
typeCacheMutex.RLock()
info := typeCache[typekey{typ, tags}] //尝试从缓存中国区
typeCacheMutex.RUnlock()
if info != nil { //获取成功
return info, nil
}
typeCacheMutex.Lock() //加锁,避免多线程多次创建
defer typeCacheMutex.Unlock()
return cachedTypeInfo1(typ, tags)
}
func cachedTypeInfo1(typ reflect.Type, tags tags) (*typeinfo, error) {
key := typekey{typ, tags}
info := typeCache[key]//再次尝试获取,确保只创建一次
if info != nil { //获取成功
return info, nil
}
typeCache[key] = new(typeinfo) //创建一个空对象
info, err := genTypeInfo(typ, tags) //实际创建对象
if err != nil { //创建失败
delete(typeCache, key)
return nil, err
}
*typeCache[key] = *info //存储到map中
return typeCache[key], err
}
func genTypeInfo(typ reflect.Type, tags tags) (info *typeinfo, err error) {
info = new(typeinfo)
if info.decoder, err = makeDecoder(typ, tags); err != nil {
return nil, err
}
if info.writer, err = makeWriter(typ, tags); err != nil {
return nil, err
}
return info, nil
}可见对每种类型,都是单例模式。上述代码中实际创建编解码器的方法是makeDecoder和makeWriter。这两个方法详见下文
encode
对于编码器的使用,一般调用Encode函数:
func Encode(w io.Writer, val interface{}) error {
if outer, ok := w.(*encbuf); ok {//判断是否是encbuf类型的writer
return outer.encode(val)
}
eb := encbufPool.Get().(*encbuf) //从并发变量池中获取一个encbuf对象
defer encbufPool.Put(eb)
eb.reset() //清空原有数据
if err := eb.encode(val); err != nil { //编码
return err
}
return eb.toWriter(w)
}编码的核心操作在encbuf的encode方法:
func (w *encbuf) encode(val interface{}) error {
rval := reflect.ValueOf(val)
ti, err := cachedTypeInfo(rval.Type(), tags{})
if err != nil {
return err
}
return ti.writer(rval, w)
}这里就接上了上一节typecache中的方法,这里通过makeWriter确定编码器
func makeWriter(typ reflect.Type, ts tags) (writer, error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return writeRawValue, nil
case typ.Implements(encoderInterface):
return writeEncoder, nil
case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(encoderInterface):
return writeEncoderNoPtr, nil
case kind == reflect.Interface:
return writeInterface, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return writeBigIntPtr, nil
case typ.AssignableTo(bigInt):
return writeBigIntNoPtr, nil
case isUint(kind):
return writeUint, nil
case kind == reflect.Bool:
return writeBool, nil
case kind == reflect.String:
return writeString, nil
case kind == reflect.Slice && isByte(typ.Elem()):
return writeBytes, nil
case kind == reflect.Array && isByte(typ.Elem()):
return writeByteArray, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeSliceWriter(typ, ts)
case kind == reflect.Struct:
return makeStructWriter(typ)
case kind == reflect.Ptr:
return makePtrWriter(typ)
default:
return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ)
}
}就是简单的根据不同的类型创建不同的编码方法,以string为例:
func writeString(val reflect.Value, w *encbuf) error {
s := val.String()
if len(s) == 1 && s[0] <= 0x7f {//只有一个字符,且小于128
w.str = append(w.str, s[0])
} else {
w.encodeStringHeader(len(s))//添加前缀
w.str = append(w.str, s...)
}
return nil
}
func (w *encbuf) encodeStringHeader(size int) {
if size < 56 { //长度小于56
w.str = append(w.str, 0x80+byte(size))//前缀是128+长度
} else { //其他情况
sizesize := putint(w.sizebuf[1:], uint64(size)) //将长度的大端表示写入sizebuf
w.sizebuf[0] = 0xB7 + byte(sizesize) //第一个前缀183+字符串长度在大端表示后的长度
w.str = append(w.str, w.sizebuf[:sizesize+1]...)//拼接第二个前缀,字符串长度的大端表示
}
}详细过程见注释,基本过程和RLP定义的一样。对于结构体可能有些特殊:
func makeStructWriter(typ reflect.Type) (writer, error) {
fields, err := structFields(typ) //分析结构体每个字段,根据情况指定每个字段的编码方法
if err != nil {
return nil, err
}
writer := func(val reflect.Value, w *encbuf) error { //编码器具体方法
lh := w.list()
for _, f := range fields {
if err := f.info.writer(val.Field(f.index), w); err != nil {
return err
}
}
w.listEnd(lh)
return nil
}
return writer, nil
}
// go-ethereum\rlp\typecache.go
func structFields(typ reflect.Type) (fields []field, err error) {
for i := 0; i < typ.NumField(); i++ {
if f := typ.Field(i); f.PkgPath == "" { // 若果是可导出的,也就是首字母大写,PkgPath为空,不可导出会返回包名
tags, err := parseStructTag(typ, i)//解析每个字段的标签,就是字段后``中定义的
if err != nil {
return nil, err
}
if tags.ignored {
continue
}
info, err := cachedTypeInfo1(f.Type, tags)//根据类型获取cachedTypeInfo,包含编解码器
if err != nil {
return nil, err
}
fields = append(fields, field{i, info})
}
}
return fields, nil
}
func parseStructTag(typ reflect.Type, fi int) (tags, error) {
f := typ.Field(fi)
var ts tags
for _, t := range strings.Split(f.Tag.Get("rlp"), ",") {
switch t = strings.TrimSpace(t); t {
case "":
case "-":
ts.ignored = true
case "nil":
ts.nilOK = true
case "tail":
ts.tail = true
if fi != typ.NumField()-1 {
return ts, fmt.Errorf(`rlp: invalid struct tag "tail" for %v.%s (must be on last field)`, typ, f.Name)
}
if f.Type.Kind() != reflect.Slice {
return ts, fmt.Errorf(`rlp: invalid struct tag "tail" for %v.%s (field type is not slice)`, typ, f.Name)
}
default:
return ts, fmt.Errorf("rlp: unknown struct tag %q on %v.%s", t, typ, f.Name)
}
}
return ts, nil
}结构体类型的虽然复杂,但也是具体到每个字段执行不同的序列化方法,最后进行拼接。
decode
对于解码器一般调用Decode函数:
func Decode(r io.Reader, val interface{}) error {
return NewStream(r, 0).Decode(val)
}
func (s *Stream) Decode(val interface{}) error {
if val == nil {
return errDecodeIntoNil
}
rval := reflect.ValueOf(val)
rtyp := rval.Type()
if rtyp.Kind() != reflect.Ptr { //判断是否为指针类型
return errNoPointer
}
if rval.IsNil() {
return errDecodeIntoNil
}
info, err := cachedTypeInfo(rtyp.Elem(), tags{}) //获取编解码方法
if err != nil {
return err
}
err = info.decoder(s, rval.Elem())//解码
if decErr, ok := err.(*decodeError); ok && len(decErr.ctx) > 0 {
decErr.ctx = append(decErr.ctx, fmt.Sprint("(", rtyp.Elem(), ")"))
}
return err
}注意decode的逻辑是从Stream中获取源数据,最后解析到val中,所以需要val是一个指针类型,接下来又回到typecache中,通过判断val的类型获取所需的解码器。
func makeDecoder(typ reflect.Type, tags tags) (dec decoder, err error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return decodeRawValue, nil
case typ.Implements(decoderInterface):
return decodeDecoder, nil
case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(decoderInterface):
return decodeDecoderNoPtr, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return decodeBigInt, nil
case typ.AssignableTo(bigInt):
return decodeBigIntNoPtr, nil
case isUint(kind):
return decodeUint, nil
case kind == reflect.Bool:
return decodeBool, nil
case kind == reflect.String:
return decodeString, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeListDecoder(typ, tags)
case kind == reflect.Struct:
return makeStructDecoder(typ)
case kind == reflect.Ptr:
if tags.nilOK {
return makeOptionalPtrDecoder(typ)
}
return makePtrDecoder(typ)
case kind == reflect.Interface:
return decodeInterface, nil
default:
return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ)
}
}以string为例:
func decodeString(s *Stream, val reflect.Value) error {
b, err := s.Bytes()
if err != nil {
return wrapStreamError(err, val.Type())
}
val.SetString(string(b)) //还原为string
return nil
}
func (s *Stream) Bytes() ([]byte, error) {
kind, size, err := s.Kind()
if err != nil {
return nil, err
}
switch kind {
case Byte:
s.kind = -1
return []byte{s.byteval}, nil
case String:
b := make([]byte, size) //根据数据长度指定byte数组
if err = s.readFull(b); err != nil { //读取原始数据
return nil, err
}
if size == 1 && b[0] < 128 {
return nil, ErrCanonSize
}
return b, nil
default:
return nil, ErrExpectedString
}
}
func (s *Stream) Kind() (kind Kind, size uint64, err error) {
var tos *listpos
if len(s.stack) > 0 {
tos = &s.stack[len(s.stack)-1]
}
if s.kind < 0 {
s.kinderr = nil
if tos != nil && tos.pos == tos.size {
return 0, 0, EOL
}
s.kind, s.size, s.kinderr = s.readKind() //读取原始数据类型以及长度
if s.kinderr == nil {
if tos == nil {
if s.limited && s.size > s.remaining {
s.kinderr = ErrValueTooLarge
}
} else {
if s.size > tos.size-tos.pos {
s.kinderr = ErrElemTooLarge
}
}
}
}
return s.kind, s.size, s.kinderr
}
func (s *Stream) readKind() (kind Kind, size uint64, err error) {
b, err := s.readByte() //读第一个byte
if err != nil {
if len(s.stack) == 0 {
switch err {
case io.ErrUnexpectedEOF:
err = io.EOF
case ErrValueTooLarge:
err = io.EOF
}
}
return 0, 0, err
}
s.byteval = 0
switch { //根据第一字节的只判断原始数据类型
case b < 0x80: //原始数据只有一个byte,且小于128
s.byteval = b
return Byte, 0, nil
case b < 0xB8: //原始数据长度小于56
//返回的第二个数据获得原始数据长度
return String, uint64(b - 0x80), nil
case b < 0xC0:
size, err = s.readUint(b - 0xB7)
if err == nil && size < 56 {
err = ErrCanonSize
}
return String, size, err
case b < 0xF8:
return List, uint64(b - 0xC0), nil
default:
size, err = s.readUint(b - 0xF7)
if err == nil && size < 56 {
err = ErrCanonSize
}
return List, size, err
}
}可见流程就是rlp编码的逆向过程,和我们之前讲的解码方法一样,关键是通过第一个字节获取原始数据的类型,然后推算出原始数据的长度,最后解析即可
小结
最后,go-ethereum源码中rlp实现部分还是很完整的,并且没有什么其他依赖,都使用的是go标准包,所以可以单独拿出来做一个库,以后遇到需要用rlp编码的地方,可以直接拿来使用。还有这一部分源码大量的使用了反射,对于学习go语言反射也是很好的一个素材